Coursera-Kaggle Week1 学习笔记
本篇博客为 Coursera 上一门关于 kaggle 的公开课的第一周学习笔记。
竞赛基础
- 一个竞赛涉及的主要概念包括:
- 数据
- 模型
- 提交
- 评估
- 排行榜
- 当前主要的竞赛平台有:
- Kaggle
- DrivenData
- CrowdAnalityx
- 天池 & 科赛
- 竞赛和实际应用的区别在于:
- 实际问题往往更加复杂
- 竞赛是一种很好的学习方式(不涉及提出问题、部署模型以及测试等步骤)
算法回顾
在竞赛中,常用的 ML 算法可以分为四类(以下解释基于分类问题):
- 线性模型:线性模型将空间分为两个子空间
- 基于树的方法:基于树的方法将空间分为盒子
- K近邻方法: K近邻方法主要取决于如何测量点之间的距离
- 神经网络:神经网络方法产生平滑的非线性决策边界
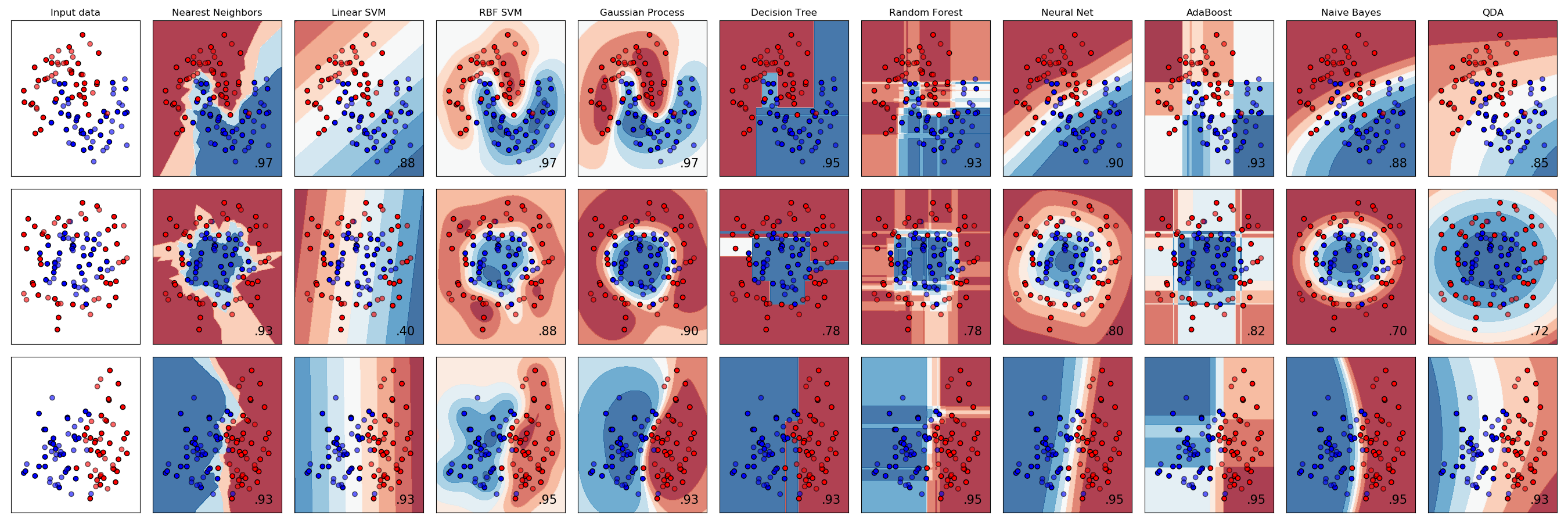
- 没有完美适用于所有问题的算法
- 一般情况下,最有效的方法是梯度提升决策树和神经网络
- 关于 GBDT 和 RF 的问题
- 如果训练一个 GBDT 或 RF 模型,并丢弃模型中的第一棵树或最后一棵树
- 对于 GBDT,其每一棵树之间互相关联,后面的树提升前面所有树的结果
- 如果丢弃第一棵树,后面所有的树都会出现偏差,总的表现会明显下降(学习率较大时)
- 如果丢弃最后一棵树,之前所有树的结果不会受到影响,总的表现变化不大
- 对于 RF,每一棵树之间相互独立,最后只是取平均
- 因此去除一棵树对结果并无较大影响
- 对于 GBDT,其每一棵树之间互相关联,后面的树提升前面所有树的结果
- 如果训练一个 GBDT 或 RF 模型,并丢弃模型中的第一棵树或最后一棵树
软硬件需求
- 硬件配置(GPU 未提及):
- 内存:越大越好
- 核心:越多越好
- 存储:SSD 最佳
- 云训练平台:
- Amazon AWS
- Microsoft Azure
- Google Cloud
- 软件推荐:
- 语言:Python!
- 基本软件栈:
- numpy:线性代数库
- pandas:数据读取与处理
- sckit-learn:机器学习算法库
- matplotlib:可视化
- IDE:jupyter notebook
- 特别软件包:
- XGBoost:基于决策树的梯度提升
- LightGBM:同上
- tsne:降维可视化
- libFM:分解机
- 深度学习:
- tensorflow
- keras
- pytorch
特征预处理与生成
- 三个主要观点:
- 特征预处理非常必要
- 特征生成是一个有力工具
- 预处理和特征生成的流水线取决于模型的类型
数值特征
- 对于树模型和非树模型,数值特征的预处理有所不同
- 树模型并不依赖于特征缩放与分级
- 非树模型非常依赖于特征缩放与分级
- 最常使用的预处理方法有:
- 基于最大最小值的缩放:缩放至 \([0,1]\):
sklearn.preprocessing.MinMaxScaler\[ X=(X-X.min ( )) /(X.max ( )-X.min ( )) \] - 基于标准差的缩放:缩放至平均值为 0,标准差为 1:
sklearn.preprocessing.StandardScaler\[ X=(X-X .mean( )) / X . std( ) \] - 异常值处理:采用剪切的方法(设置上下阈值)
- 分级:使有序变量之间的距离相等:
scipy.stats.rankdata- 可以在缩放的同时处理异常值
- 对数与幂处理:
np.log(1+x)以及np.sqrt(1+x)- 使得过大的数值更加趋向于平均值,同时也使得在原点附近的数据更容易区分
- 适用于神经网络等非线性模型
- 基于最大最小值的缩放:缩放至 \([0,1]\):
- 特征生成的驱动力为:
- 先验知识
- 探索性数据分析(EDA)
分类和序数特征
- 序数特征是一种特殊的分类特征,其中的值按某种有意义的顺序排列
- 比如船票等级、驾照等级等
- 标签编码可以将分类变量映射为数字
- 可以按照字母表顺序映射:
sklearn.preprocessing.LabelEncoder - 也可以按照在数据集中出现的顺序映射:
Pandas.factorize
- 可以按照字母表顺序映射:
- 频率编码可以将分类变量映射为其出现频率
- 对于多个频率重复的情况,可以使用
scipy.stats.rankdataencoding = titanic.groupby(‘Embarked’).size()
encoding = encoding/len(titanic)
titanic[‘enc’] = titanic.Embarked.map(encoding)
- 对于多个频率重复的情况,可以使用
- 标签和频率编码通常对基于树的模型很有用
- 有时也对线性模型有用
- 对于非树模型,通常使用独热编码处理分类变量
- 如果分类变量类别过多,考虑使用稀疏举证
- 基于分类变量的融合特征生成可以对线性模型和 KNN 产生帮助
时间与坐标特征
- 时间特征的常见类型
- 周期性特征:如 day of week
- 自从(或距离)某个事件的时间
- 行不相关事件:如距离某个共同时刻的时间
- 行相关事件:如距离下一个假日的时间(每行对应的假日时间不同)
- 两个日期之间的差值
- 坐标特征的常见类型
- 来自数据中的有趣的地点
- 坐标聚类的中心
- 聚合数据(如某个地点周边的垃圾桶数量)
- 对于树模型,可以对坐标适当旋转作为一个新的特征,提高准确率
缺失值
- 对于 NaN(Not a Number)变量,其填充方法的选择取决于具体情况
- 通常使用超出范围的特征来替代(如 -999)
- 也可以使用均值或中位数
- 有时候可以重新构建缺失值
- 通常使用超出范围的特征来替代(如 -999)
- 有时候缺失值可能已经被数据提供者进行了处理
- 可以使用二元特征 isnull 来表明哪些数据含有缺失值
- 一般来说,在进行特征生成时,避免对 NaN 进行填充
- 直接忽略这些缺失值
- XgBoost 可以直接处理 NaN 变量
- 树模型算法本身对缺失值不敏感,但实际的工具需要有专门的缺失值处理函数
- 有时候如果缺失值比例较大,可以考虑删除样本或特征
从文字和图片中提取特征
词袋模型

- 使用词袋模型的流水线:
- 预处理:
- 大小写处理、词干提取、词形还原、停用词过滤
- 建立词袋模型:基于词语出现次数
- 行对应一个句子,列对应一个词语
- 可以使用 Ngrams 体现上下文信息
- 后处理:TFIDF
- 预处理:
词向量
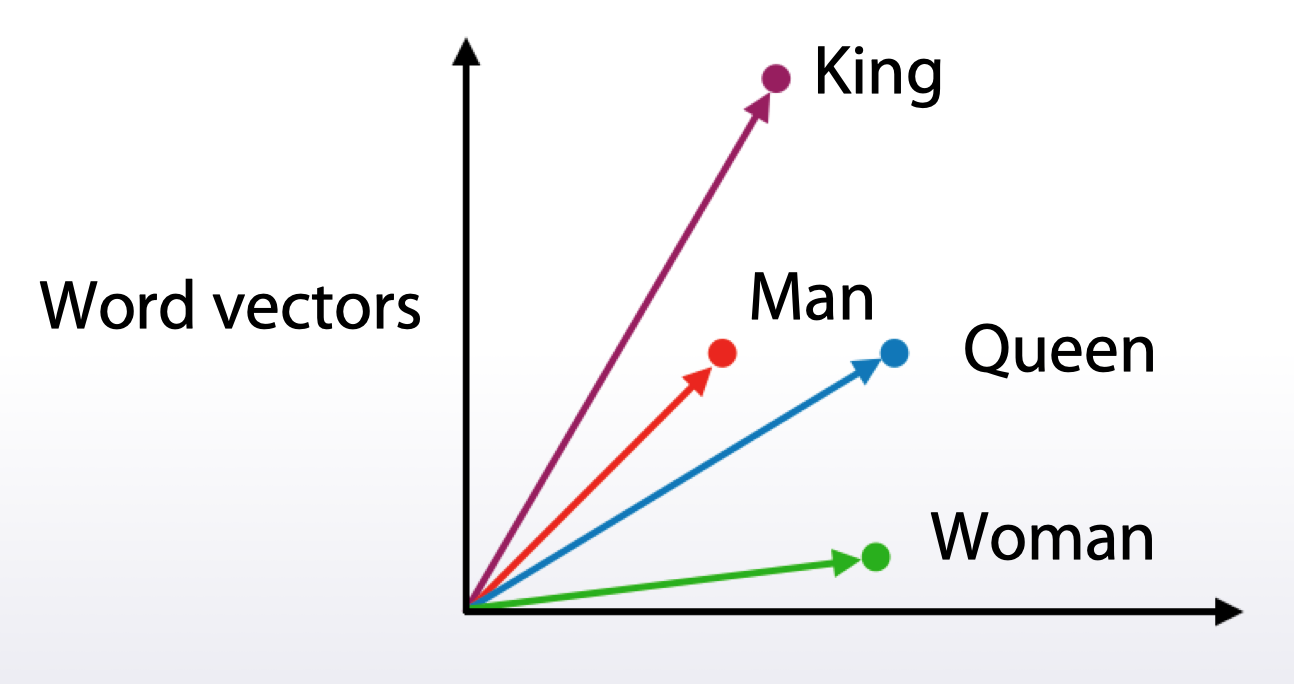
- 与词袋模型相比,得到的向量维度相对小
- 常见的词向量构建方法包括 Word2vec、Glove、FastText、BERT 等
- 还有句向量的构建方法如 Doc2vec 等
- 词向量通常是预训练好的模型
- 其向量的各维度的值可能无法解释(词袋模型可以)
- 相似语义的词语通常有相似的向量表达
- 常见的词向量构建方法包括 Word2vec、Glove、FastText、BERT 等
图片

- 通常使用卷积神经网络来处理图片
- 可以通过不同的层来提取图片特征
- 谨慎地选择预训练网络能够对特征提取提供帮助
- 对预训练模型的微调可以帮助提升效果
- 对于数据量不够的情况,通过一些手段增加数据能够提升模型表现
- 如对图片进行旋转操作
- 在测试时也可以使用数据增加来平均预测结果
作业:Pandas 基础
- 求 2014 年 9 月所有商店的收益的最大值
- 第一步:筛选出 2014 年 9 月的数据
- 第二步:对收益按商店进行分组,然后求和求最大
tran_1 = transactions[transactions["date_block_num"] == 20]
max_revenue = (tran_1["item_price"] * tran_1["item_cnt_day"]).groupby(tran_1["shop_id"]).sum().max() - 哪一个商品类别在 2014 年夏季的收益最大?
- 第一步:筛选出 2014 年 6-8 月的数据
- 第二步:将销售记录数据与商品类别数据合并
- 第三步:对收益按照商品类别分组, 然后求和求参数最大
tran_2 = transactions[(transactions["date_block_num"] >= 17) & (transactions["date_block_num"] <= 19)]
tran_2 = pd.merge(tran_2, items, how="left", on="item_id")
category_id_with_max_revenue = (tran_2["item_price"] * tran_2["item_cnt_day"]).groupby(tran_2["item_category_id"]).sum().argmax() - 有多少商品的价格一直没有发生过变化?
- 按商品 id 进行分组,并判断
nunique()是否为 1(即只有一个独特的值)- 对其求和即可得到商品的数量(True 为 1,False 为 0)
num_items_constant_price = (transactions["item_price"].groupby(transactions["item_id"]).nunique() == 1).sum()
- 按商品 id 进行分组,并判断
- 计算
shop_id为 25 的商店在 2014 年 12 月每天卖出的商品的无偏方差- 第一步:筛选出该商店的数据
- 第二步:对每天销售的商品数按日期分组,并求和
- 第三步:使用
var()求出方差
tran_3 = transactions[transactions["date_block_num"] == 23]
tran_3 = tran_3[tran_3["shop_id"] == shop_id]
tran_3 = tran_3["item_cnt_day"].groupby(tran_3["date"]).sum()
total_num_items_sold_var = tran_3.var()