Coursera-Kaggle Week2 学习笔记
本篇博客为 Coursera-Kaggle 公开课的第二周学习笔记。
探索式数据分析
EDA 介绍
- EDA 的作用:
- 更加了解数据
- 找到一些 magic 特征
- 在探究模型(比如进行 stacking)之前,先进行 EDA
- 附:stacking 是一种集成学习方法
- 在具体进行 EDA 之前,先要建立对数据的直觉:
- 首先需要了解相关的领域知识
- 可以帮助更深层次地理解问题
- 检查数据是否符合直觉
- 是否和领域知识相契合
- 了解数据是如何生成的
- 这对建立正确的验证方式非常重要
- 首先需要了解相关的领域知识
匿名数据
- 关于匿名数据:
- 我们需要尝试去解码这些特征
- 即猜测该特征的真实含义
- 我们需要猜测特征的类型
- 每种类型对应的预处理方式不同
- 可能有用的函数:
df.dtypes # dataframe各列数据类型
df.info() # dataframe信息(index和各列数据类型)
x.value_counts() # 某个特征项中各数值数量统计
x.isnull() # 某个特征项是否包含NA(such as None or numpy.NaN) pandas基于numpy构建
- 我们需要尝试去解码这些特征
数据可视化
数据可视化可以分为两类:
第一类:探索单个特征
- 直方图:
plt.hist(x)

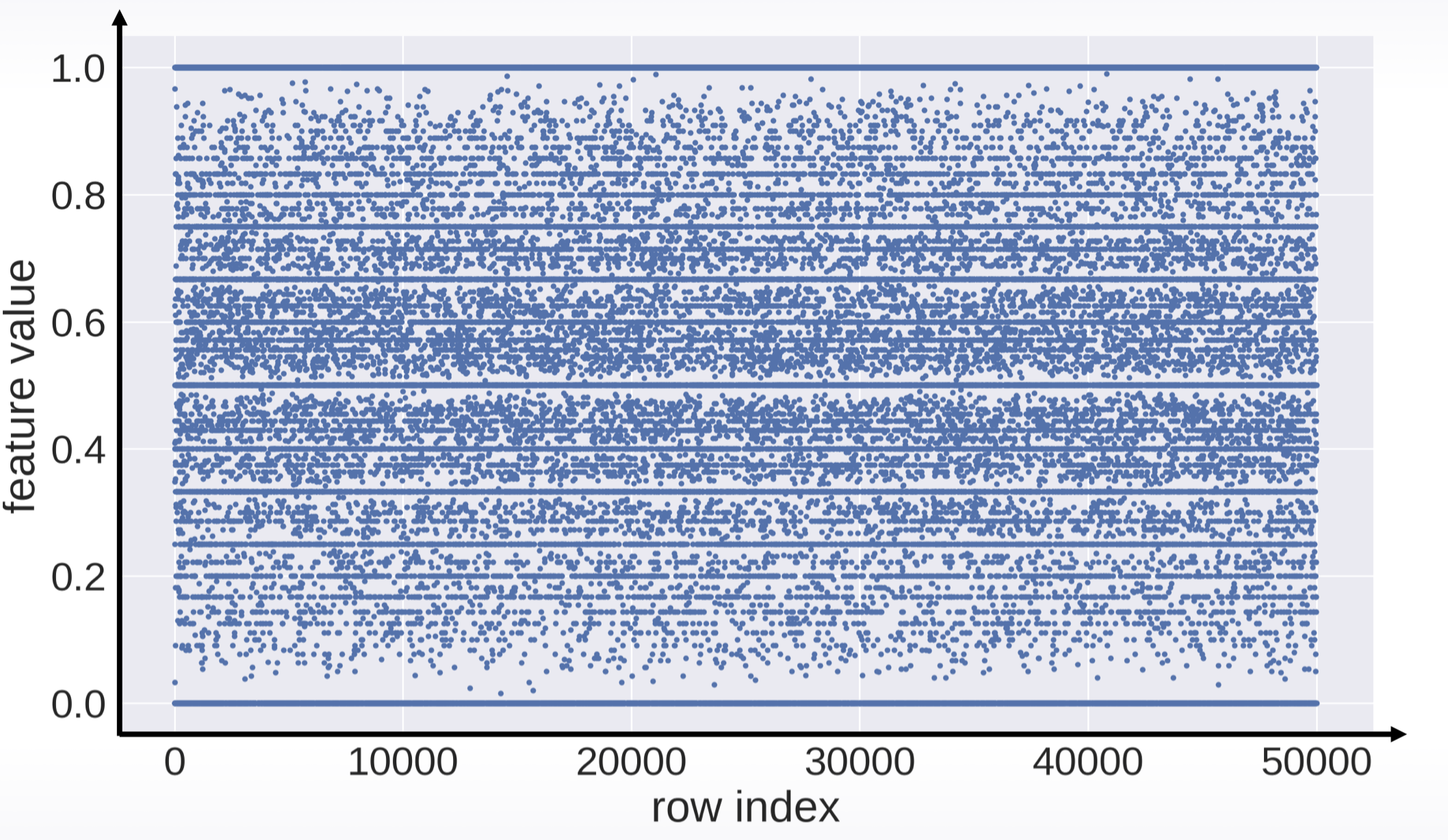
- 索引与值:
plt.plot(x, ‘.’)
统计量分析:
df.describe()
x.mean()
x.var()其他统计:
x.value_counts()
x.isnull()
第二类:探索特征间的关联性
- 特征对
散点图:
plt.scatter(x1, x2)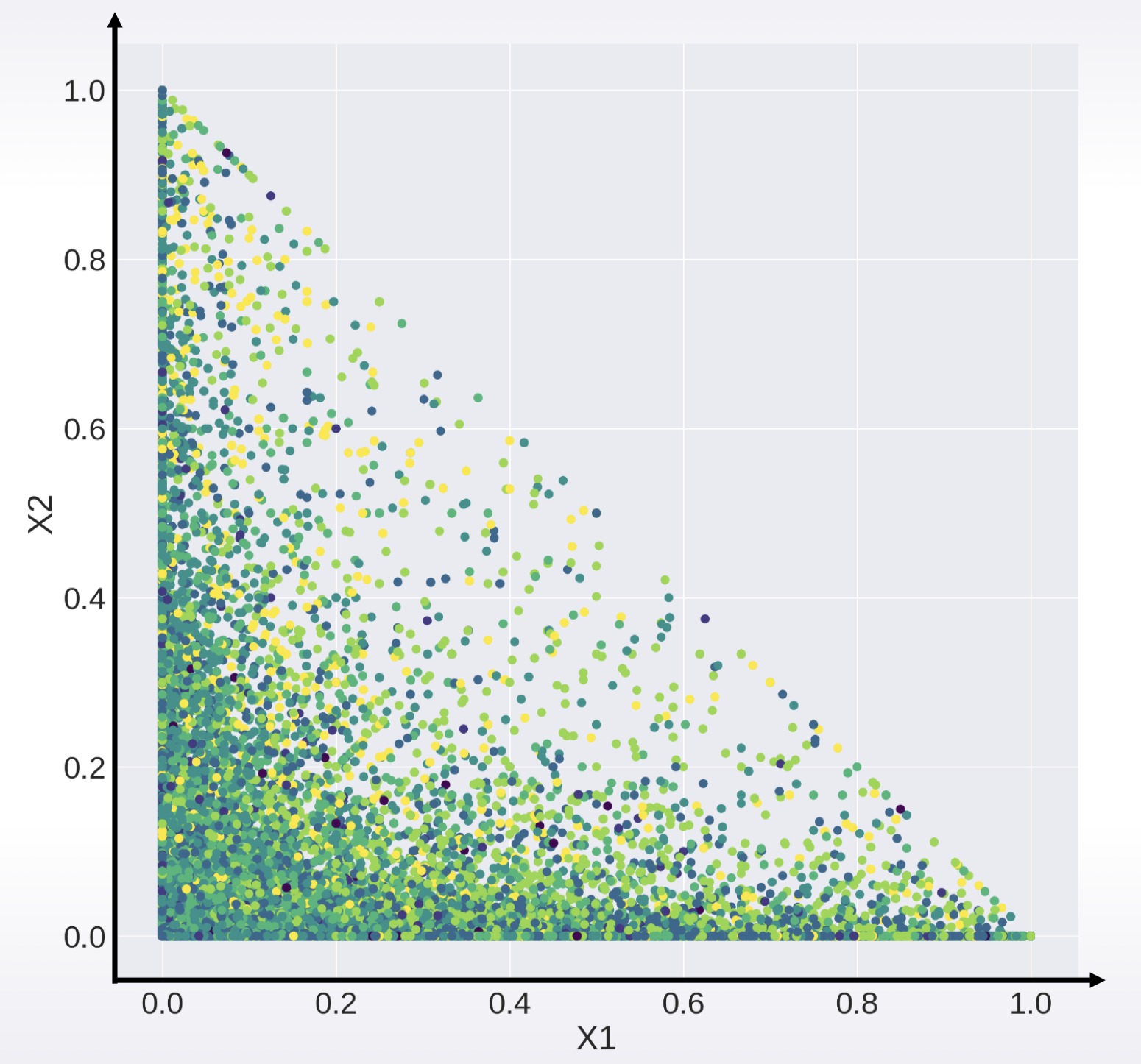
散点矩阵:
pd.scatter_matrix(df)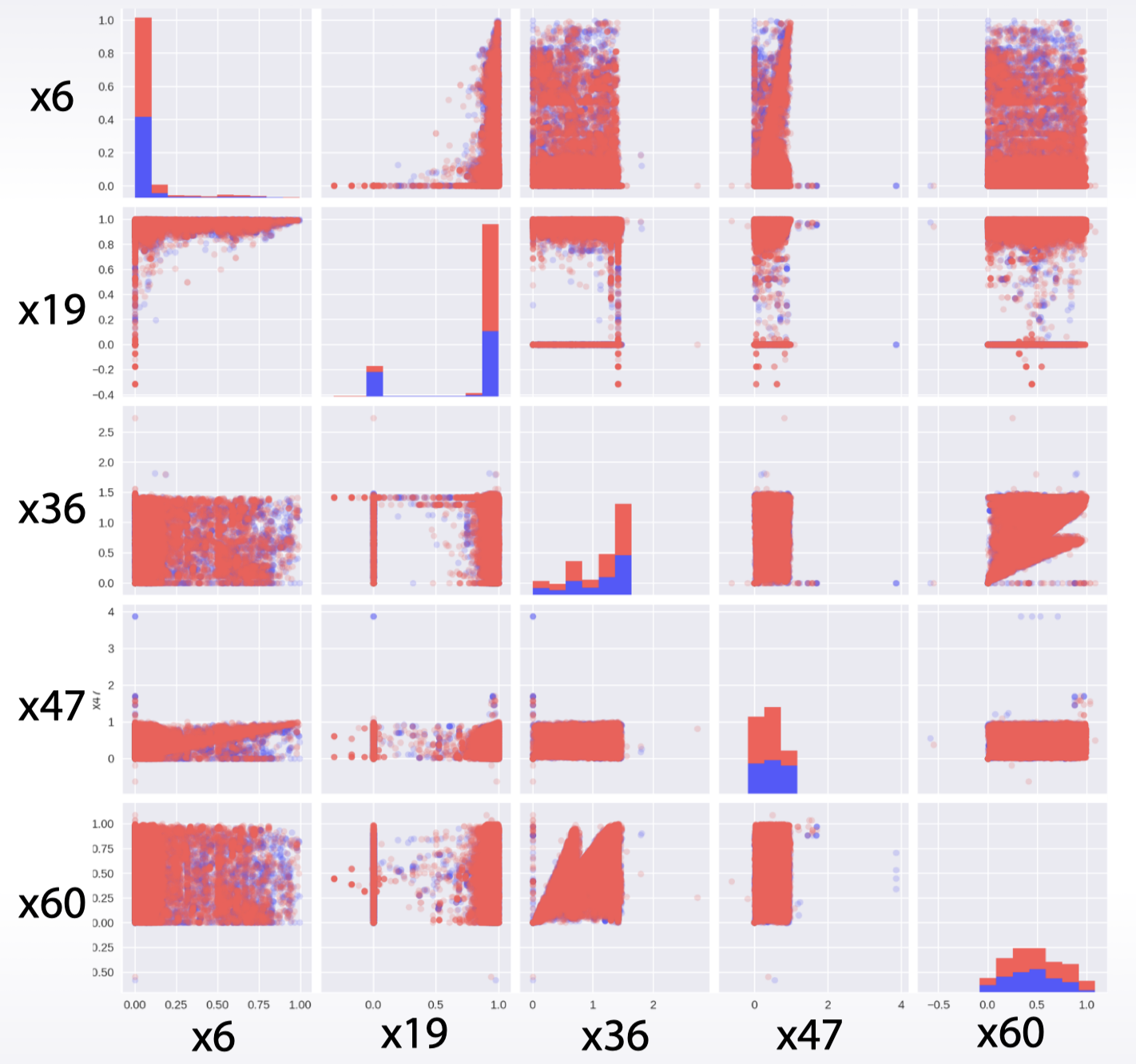
相关系数图:
df.corr(), plt.matshow( … )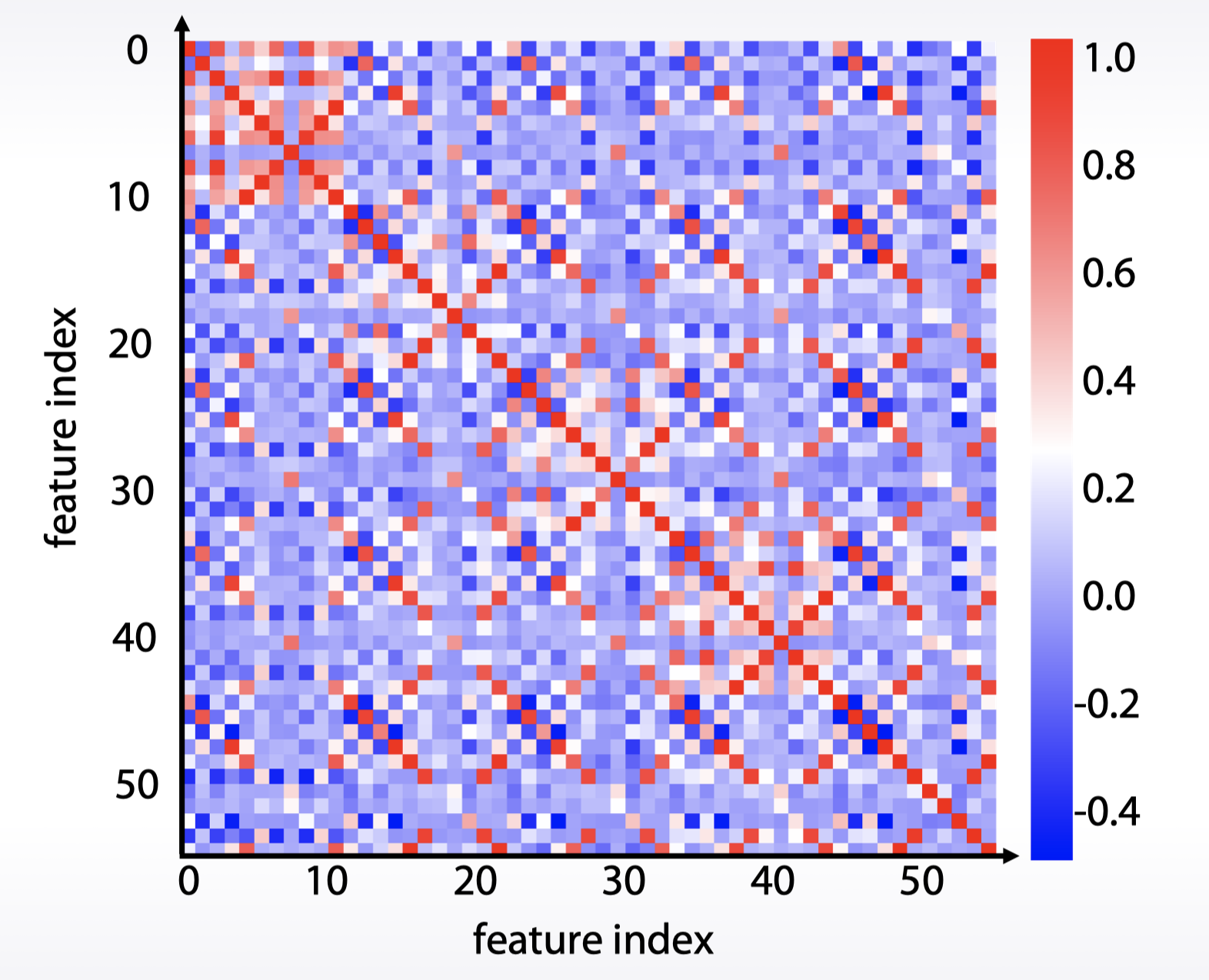
- 特征组
相关系数图 + 聚类
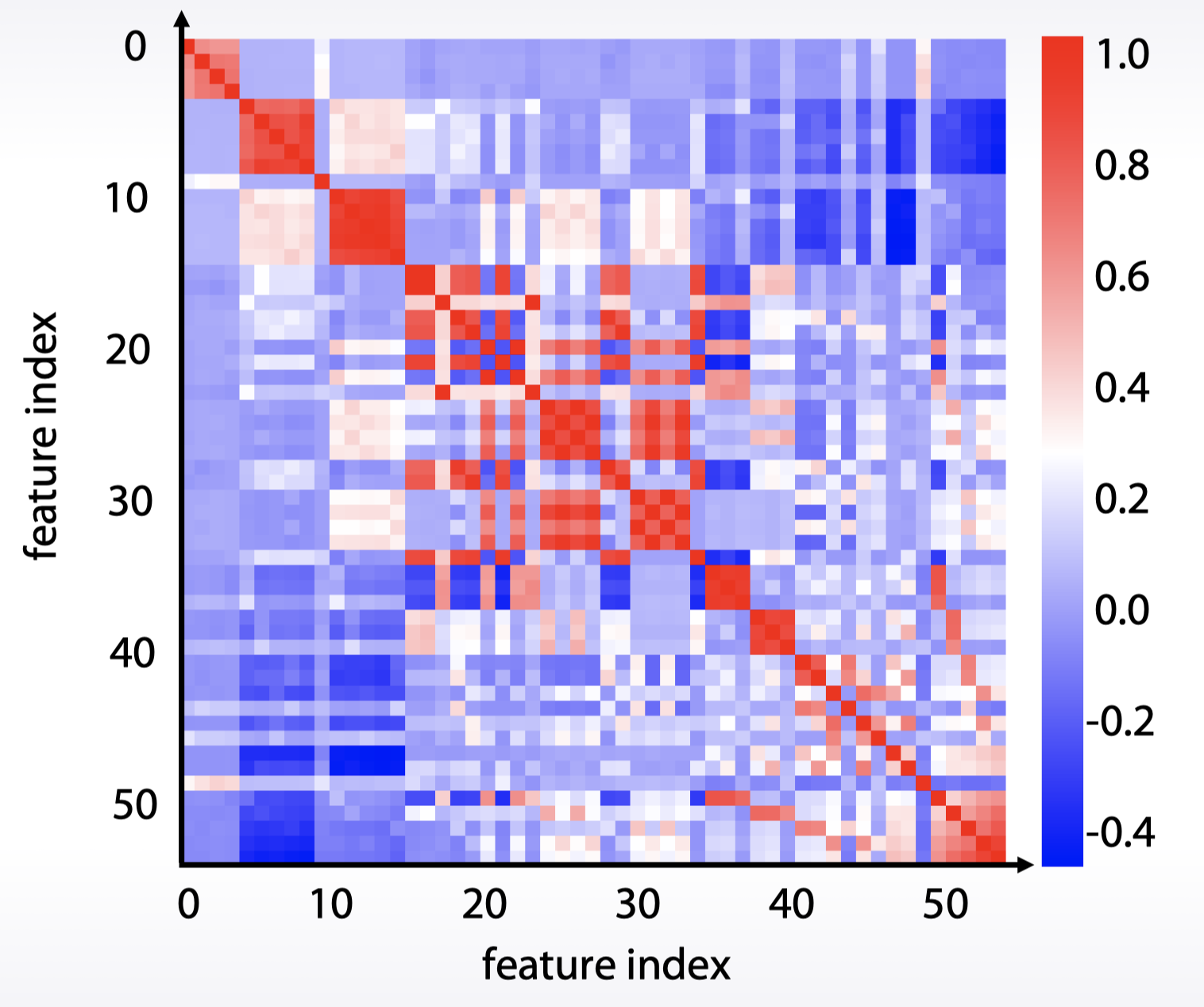
索引与值(基于统计量):
df.mean().sort_values().plot(style=’.’)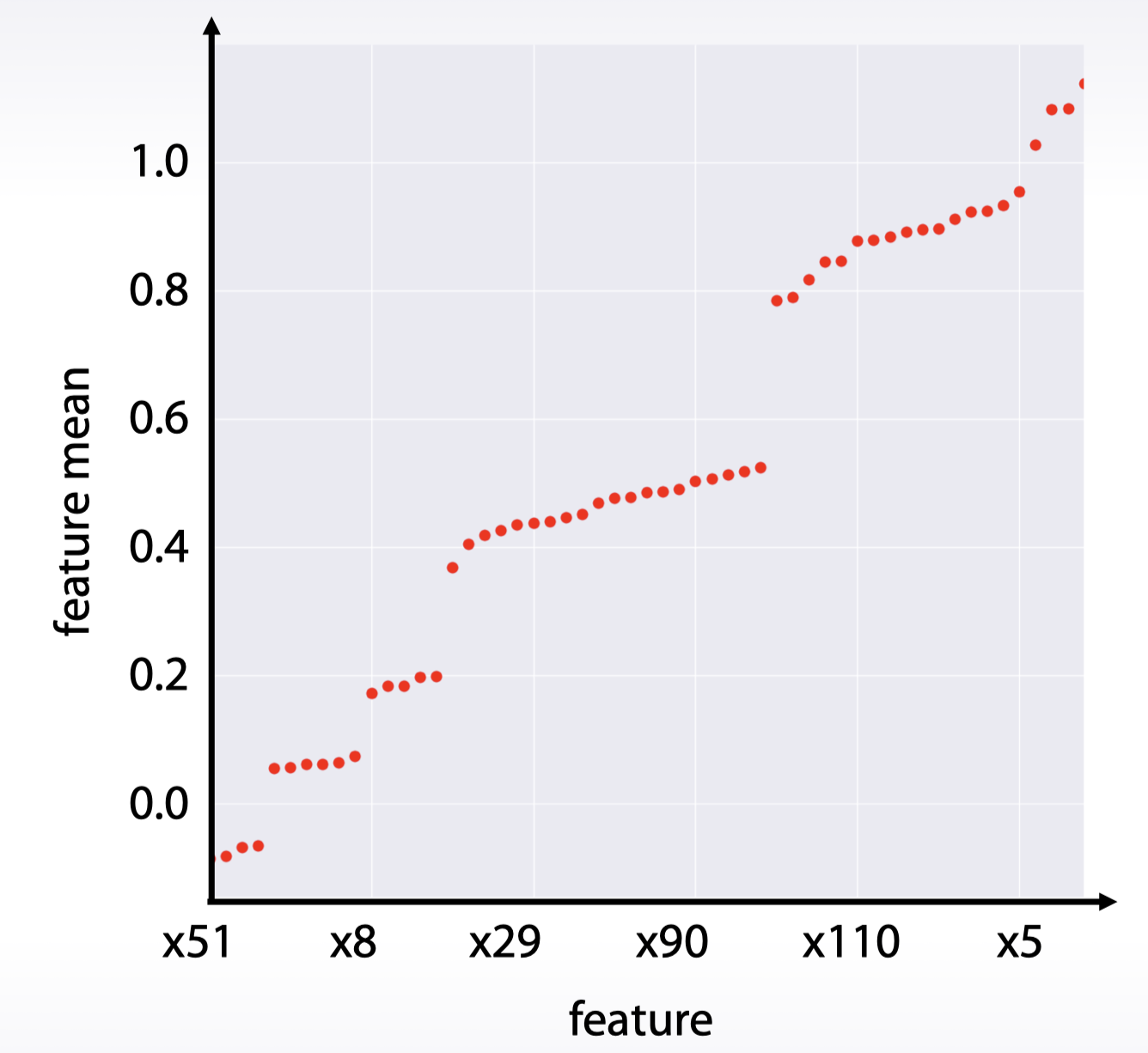
数据集清理与检查
- 数据集清理包括:
- 常数特征的清理:
traintest.nunique(axis=1) == 1 - 重复特征的清理:
traintest.T.drop_duplicates()如果对于一些分类特征,其实际上是重复的(只要把名字替换)
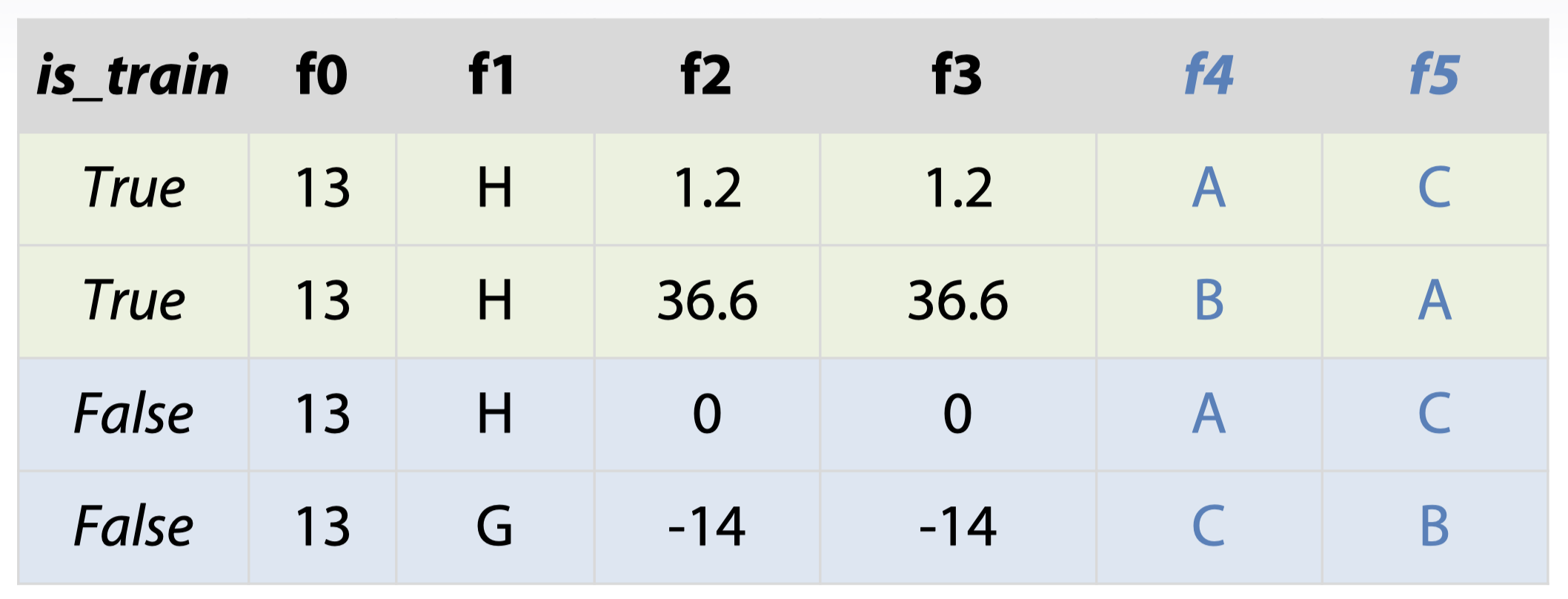
这种情况可以先给分类变量重新命名(自顶向下,第一个变量为 1,第二个为 2,以此类推)
for f in categorical_feats:
traintest[f] = traintest[f].factorize()
traintest.T.drop_duplicates()
- 常数特征的清理:
- 其他检查包括:
- 检查是否有重复的数据行
- 如果有,理解其为什么重复(并不一定要删除)
- 检查是否有打乱数据
可以通过画图来确认
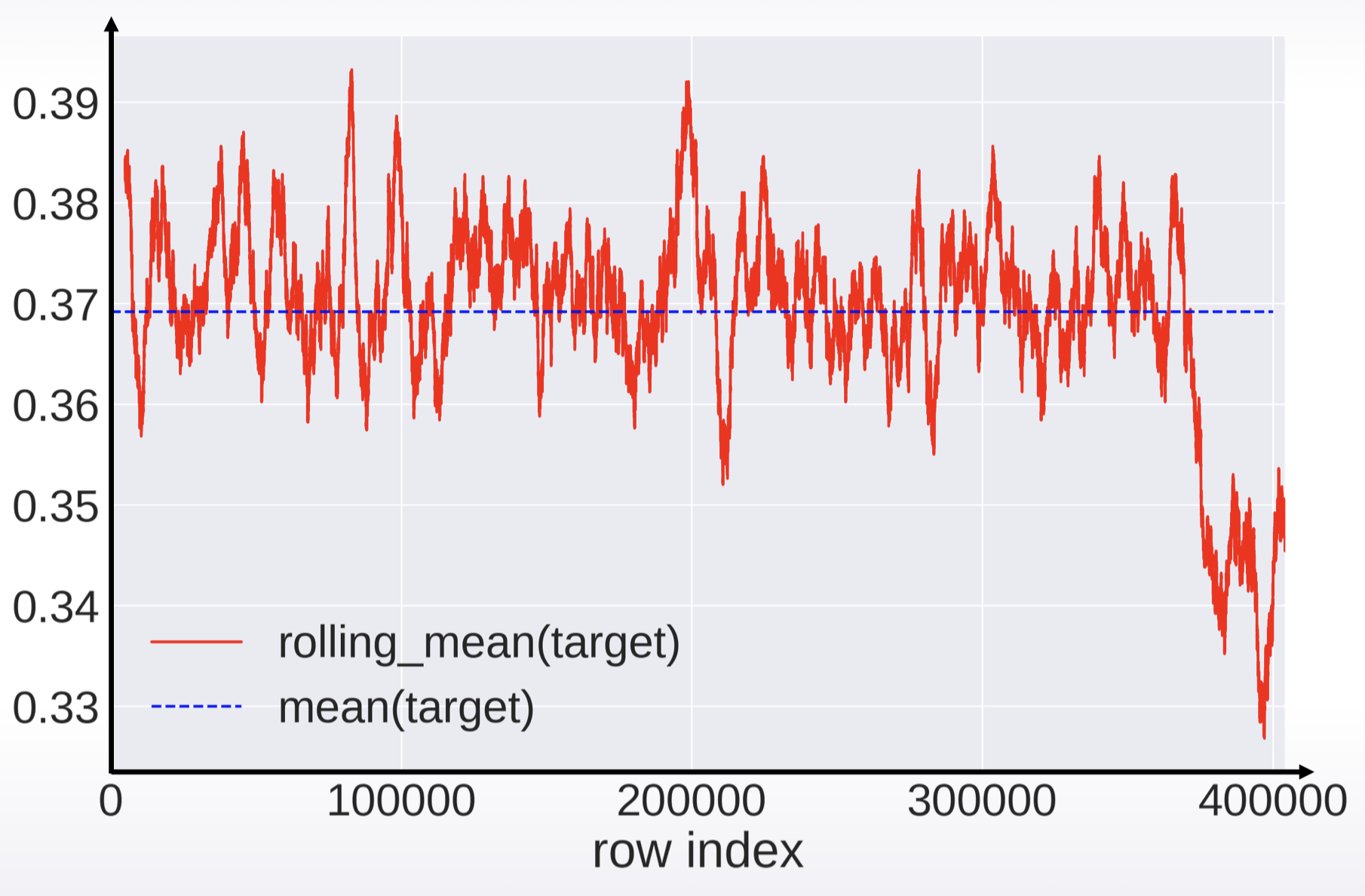
如果没有打乱数据,则可能存在数据泄露
- 检查是否有重复的数据行
验证与过拟合
简介
- 验证帮助我们评估一个模型的质量
- 选择在未知数据(验证集)上表现最好的模型
- 欠拟合指模型未捕获数据足够的模式
- 一般来说,过拟合指模型在验证集上的表现明显低于训练集,原因在于:
- 捕获了噪声
- 捕获了无法推广到测试数据的模式
- 在竞赛中,过拟合指模型在测试(公开/私有)集上的表现比验证集的表现要差
验证策略
- 有三种主要的验证策略:
- 保留验证(Hold-out)
sklearn.model_selection.ShuffleSplit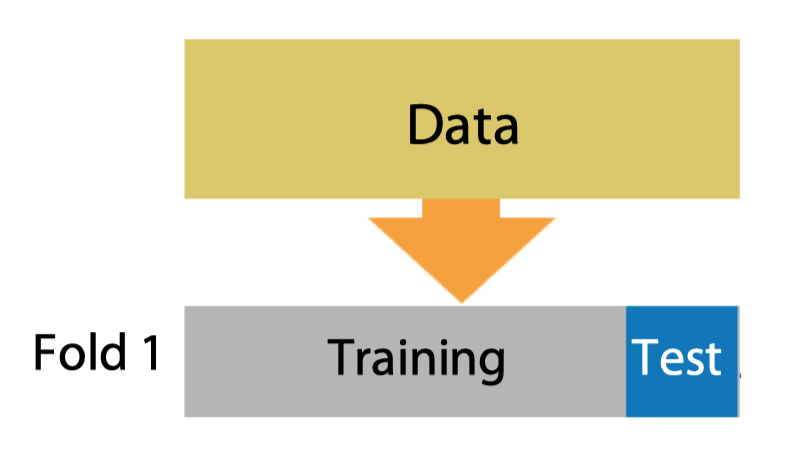
- K 保留验证(K-fold)
sklearn.model_selection.Kfold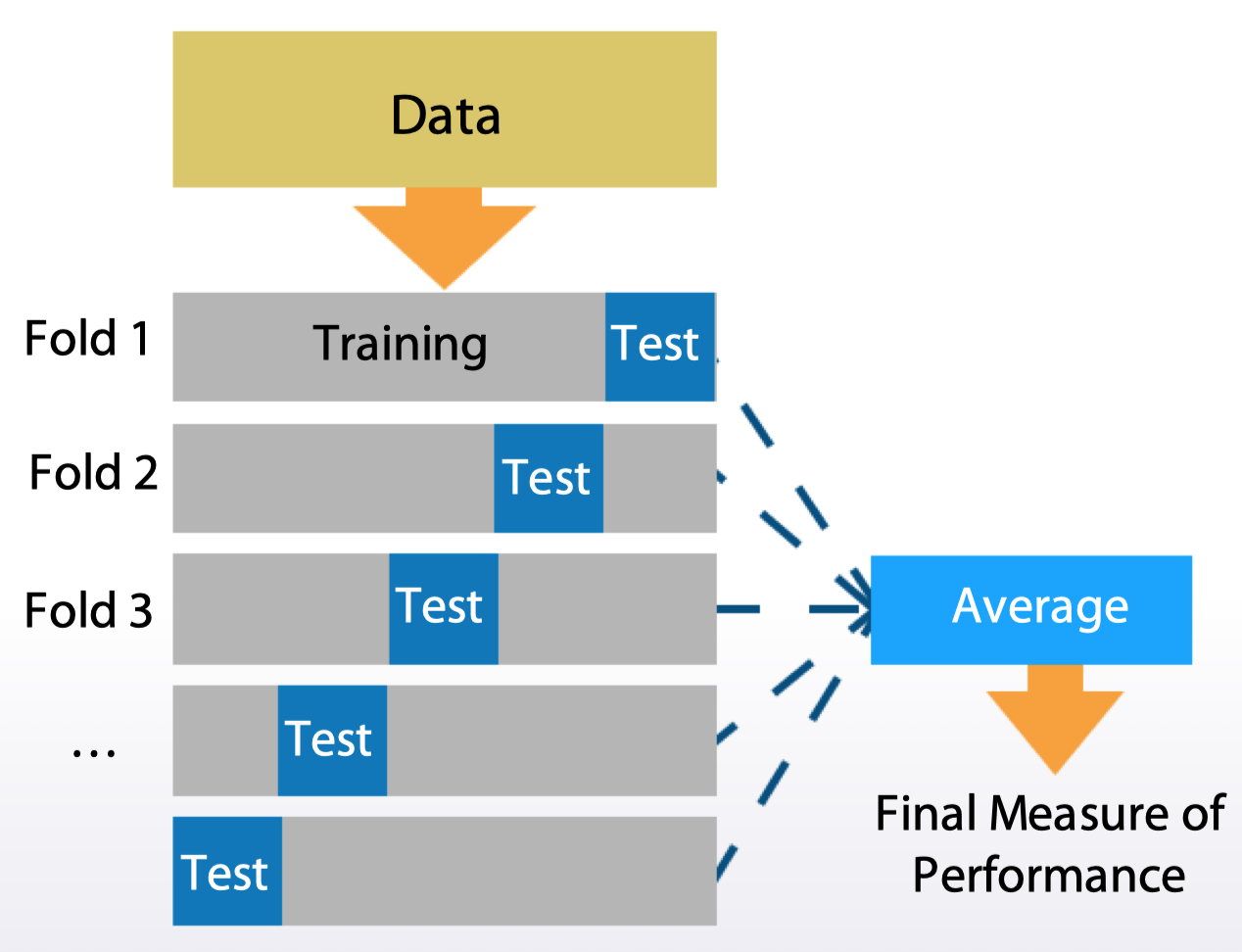
- 留一验证(Leave-one-out)
sklearn.model_selection.LeaveOneOut
- 保留验证(Hold-out)
- 对于某些情况,上述验证方法可能会存在偏差:
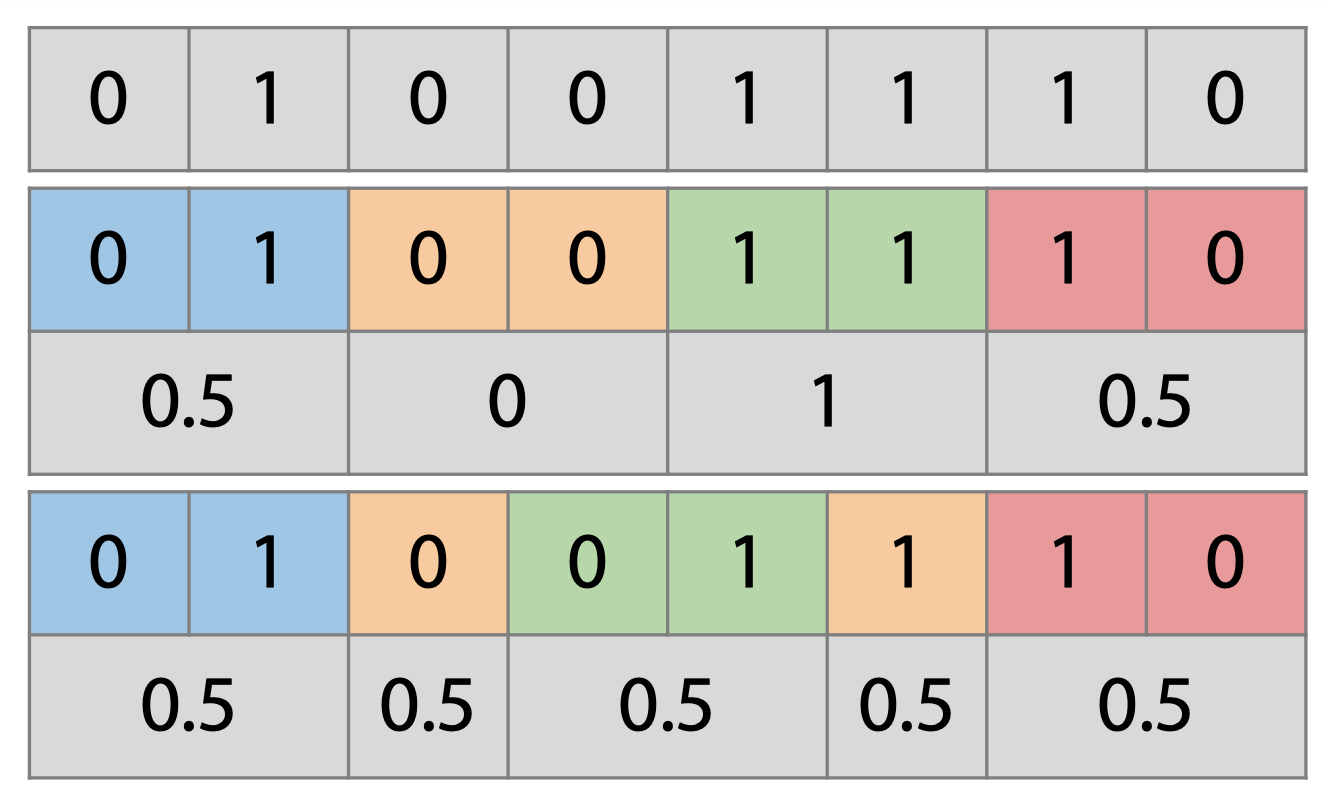
- 例如上面这个小数据集,如果分割不当,可能会导致训练结果产生偏差
- 这时我们需要采用分层的方法,来保证各 fold 之间类别的比例与总比例相同
- 分层方法主要针对:
- 小样本数据
- 不平衡数据
- 多分类数据
数据划分策略
- 在大部分情况下,数据划分的方式有以下三种(单独使用或结合起来):
- 根据 row number(随机分)
- 根据时间
- 根据数据的 id
- 特征生成的逻辑需要基于数据划分的策略
- 基本原则:验证集的划分应该模仿竞赛中训练/测试集的划分
验证的常见问题
- 验证时出现的问题可以分为两个阶段:
- 本地验证阶段
- 提交阶段
- 在本地验证阶段,如果得到了低于期望的分数,我们应该进行进一步的验证:
- 进行不同的 K 保留验证,并求得分均值
- 在一个分割上调试模型,在另一个分割上分析得分(对于 K 保留)
- 在提交阶段,如果分数不如本地验证的得分,我们应该:
- 检查公开排行榜的数据是否过少(无需处理)
- 检查是否存在过拟合(需要处理)
- 检查是否选择了正确的划分策略(需要处理)
- 检查训练集和测试集是否属于不同的分布(需要处理)
- 可以考虑对输出进行批量处理
- 有时候,不用过分在意公开排行榜的得分,因为存在以下情况:
- 随机化处理
- 例如所有参赛者的得分过于接近,因此平台做了随机处理来区分得分
- 数据量过小
- 公开榜与私有榜的分布不同
- 随机化处理
数据泄露
- 数据泄露是在竞赛中特有的一种现象
- 本质上是一种因果关系的纰漏(倒因为果)
- 有时候利用数据泄露可以拿到非常好的成绩
- 常见的数据泄露包括:
- 时间序列上的泄露
- ID 信息
- 元数据
- 行的顺序
- 与数据泄露相关的一项技术是排行榜探索(leaderboard probing)
- 该技术是利用排行榜的得分来计算 id 与输出类别之间的关系
- 对于二元分类的对数损失函数,其测试数据的均值可以用如下公式求出: \[
\frac{N_{1}}{N}=\frac{-L-\ln (1-C)}{\ln C-\ln (1-C)}
\]
- L:排行榜得分
- C:预测的常数
- 对于二元分类的对数损失函数,其测试数据的均值可以用如下公式求出: \[
\frac{N_{1}}{N}=\frac{-L-\ln (1-C)}{\ln C-\ln (1-C)}
\]
- 个人感想:不一定有用
- 该技术是利用排行榜的得分来计算 id 与输出类别之间的关系
作业:数据泄露
整体思路:
- 先提交全为 1 的预测,得到评分为 0.5
- 说明测试集中正负样本各一半
- 基于两个特征 id 的共现矩阵,计算每一组 id 对的相似性
- 共现矩阵对称,通过向量点积计算
- 发现相似性得分以 20 为分界,各占 50%
- 基于该分界,预测正负样本,准确率接近 99%