LDA 原理第二部分:文本分析的参数估计(下)
本篇博客为对 LDA 的原理解读第二篇的下半部分,参考论文《Parameter estimation for text analysis》的前半部分(version 2.9)。
隐含狄利克雷分布
LDA 是一个概率生成模型,用于通过无监督学习估计多项式观察的属性。在文本建模领域,LDA 对应于一种被称为潜在语义分析(LSA)的方法,LSA 的核心思想是找出文本中所蕴含的主题,该主题能够反映出文本的真实含义。我们可以通过文本中单词的共现结构来恢复出潜在的主题结构。LDA 本质上是对 PLSA(基于概率的潜在语义分析)的拓展,其引入参数的先验分布,定义了一个完整的生成过程。
混合模型
LDA 是一种混合模型,即通过组件概率分布的凸组合来对观察过程建模。凸组合指加权因子和为 1 的加权和。在 LDA 中,一个词语 \(w\) 由一个主题 \(z\) 的凸组合生成,如下所示: \[ p(w=t)=\sum_{k} p(w=t | z=k) p(z=k), \quad \sum_{k} p(z=k)=1 \tag{55} \] 其中每个混合组件 \(p(w=t | z=k) p(z=k)\) 是对应于潜在主题 \(z=k\) 的词语的多项分布,加权因子为 \(p(z=k)\). 需要注意的是,LDA 并不是基于全局的主题分布加权,而是基于词语所属文档的主题分布加权,即 \(p(z=k|d=m)\).
基于上述表述,我们可以给出 LDA 推理的主要目标:
- 给出每个主题 \(k\) 下的词语分布概率 \(p(t | z=k)=\vec{\varphi}_{k}\)
- 给出每篇文档 \(m\) 下的主题分布概率 \(p(z | d=m)=\vec{\vartheta}_{m}\)
估计参数集 \(\underline{\Phi}=\left\{\vec{\varphi}_{k}\right\}_{k=1}^{K}\) 和 \(\underline{\Theta}=\{\vec{\vartheta}_{m}\}_{m=1}^{M}\) 是对词语及文档潜在语义表达的基础。
生成模型
为了给出推理策略,我们将 LDA 看作一个生成过程。下图给出了 LDA 的贝叶斯网络:
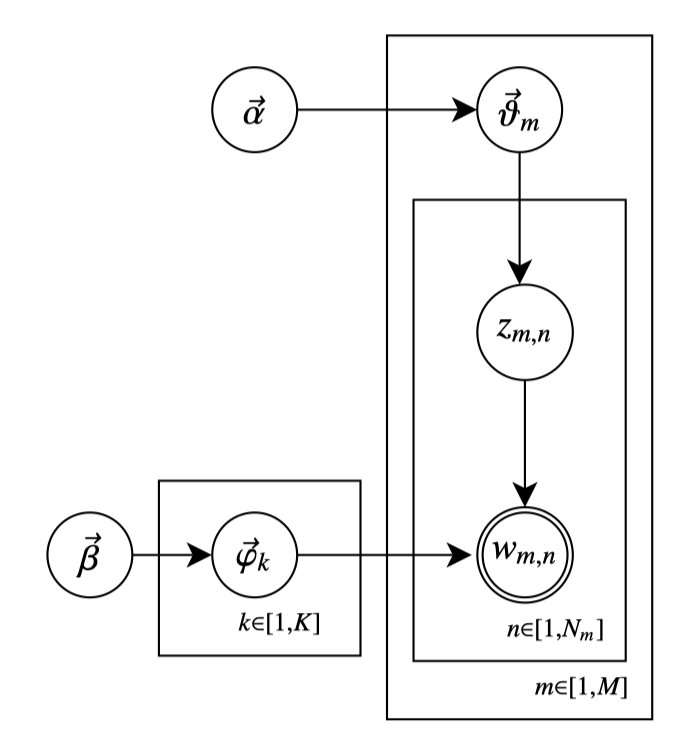
我们可以通过如下生成过程理解该贝叶斯网络:
LDA 以文档 \(\vec{w}_m\) 为划分,生成观察词语流 \(w_{m,n}\).
- 对于整个语料库,为每个主题生成一个主题-词语概率向量 \(\vec{\varphi}_k\)
- 对于每篇文档,生成一个文档-主题概率向量 \(\vec{\vartheta}_m\)
- 对于每个词语,先基于文档-主题分布概率 \(\vec{\vartheta}_m\) 生成一个主题 \(z_{m,n}\),再基于对应的主题-词语分布概率 \(\vec{\varphi}_{z_{m, n}}\) 生成一个词语 \(w_{m,n}\)
下图给出了完整的生成过程和符号表述:


似然函数
基于贝叶斯网络的拓扑结构,我们可以给出一篇文档的全数据似然函数,即给定超参数下所有已知和隐藏变量的联合分布: \[ p(\vec{w}_{m}, \vec{z}_{m}, \vec{\vartheta}_{m}, \underline{\Phi} | \vec{\alpha}, \vec{\beta})=\overbrace{\underbrace{\prod_{n=1}^{N_{m}} p(w_{m, n} | \vec{\varphi}_{z_{m,n}}) p(z_{m, n} |\vec{\vartheta}_{m}) }_{\text{word plate}}\cdot p(\vec{\vartheta}_{m} | \vec{\alpha})}^{\text{document plate (1 document)}} \cdot \underbrace{p(\underline{\Phi} | \vec{\beta})}_{\text {topic plate }} \tag{56} \] 而对于单个词语 \(w_{m,n}\),其为特定词语 \(t\) 的概率如下: \[ p(w_{m, n}=t | \vec{\vartheta}_{m}, \underline{\Phi})=\sum_{k=1}^{K} p(w_{m, n}=t | \vec{\varphi}_{k}) p(z_{m, n}=k | \vec{\vartheta}_{m}) \tag{57} \] 即之前所述的混合模型。整个语料库的似然函数为各文档的似然函数相乘(独立事件): \[ p(\mathcal{W} | \underline{\Theta}, \underline{\Phi})=\prod_{m=1}^{M} p(\vec{w}_{m} | \vec{\vartheta}_{m}, \underline{\Phi})=\prod_{m=1}^{M} \prod_{n=1}^{N_{m}} p(w_{m, n} | \vec{\vartheta}_{m}, \underline{\Phi}) \tag{58} \]
基于吉布斯采样的推理
虽然 LDA 看上去并不复杂,但进行精确的推理(求解)是十分困难的。因此我们需要使用近似推理算法,这里使用的方法是吉布斯采样。
吉布斯采样(Gibbs Sampling)是马尔科夫链蒙特卡洛模拟(MCMC)的一个特例,可用于为高维模型(如 LDA)的近似推理提供相对简单的算法。MCMC 方法可以通过马尔科夫链的平稳行为来采样高维概率分布 \(p(\vec{x})\) ,即当马尔科夫链达到稳定状态时,每一次传递生成的样本服从平稳分布,我们只需要想办法让平稳分布为待采样分布。
吉布斯采样的思路是:每次只更新分布中的一个维度 \(x_i\) ,以除去该维度的其他维度 \(\vec{x}_{\neg i}\) 为条件:
- 选择一个维度 \(i\)(随机或按某种顺序)
- 基于 \(p(x_i|\vec{x}_{\neg i})\) 采样 \(x_i\)
最终收敛后的得到的样本即为 \(p(\vec{x})\) 的样本。
为了构建一个吉布斯采样器,我们需要找出单变量条件分布 \(p(x_i|\vec{x}_{\neg i})\),可以通过下式计算: \[ p\left(x_{i} | \vec{x}_{\neg i}\right)=\frac{p(\vec{x})}{p\left(\vec{x}_{-i}\right)}=\frac{p(\vec{x})}{\int p(\vec{x}) \mathrm{d} x_{i}} \text { with } \vec{x}=\left\{x_{i}, \vec{x}_{\neg i}\right\} \tag{59} \] 而对于包含隐藏变量 \(\vec{z}\) ,我们一般想要知道其后验分布 \(p(\vec{z} | \vec{x})\)。基于式 \((59)\) ,吉布斯采样器的公式如下: \[ p\left(z_{i} | \vec{z}_{\neg i}, \vec{x}\right)=\frac{p(\vec{z}, \vec{x})}{p\left(\vec{z}_{\neg i}, \vec{x}\right)}=\frac{p(\vec{z}, \vec{x})}{\int_{Z} p(\vec{z}, \vec{x}) \mathrm{d} z_{i}} \tag{60} \] 其中的积分对于离散变量来说为求和。基于吉布斯采样得到足够的样本 \(\tilde{\vec{z}}_{r}, r \in[1, R]\) 后,我们可以通过下式来估计潜在变量的后验分布: \[ p(\vec{z} | \vec{x}) \approx \frac{1}{R} \sum_{r=1}^{R} \delta\left(\vec{z}-\tilde{z}_{r}\right) \tag{61} \] 其中克罗内克函数 \(\delta(\vec{u})=\{1 \text { if } \vec{u}=0 ; 0 \text { otherwise }\}\).
LDA 吉布斯采样器
下面我们将给出 LDA 的吉布斯采样的详细过程。
我们将使用上述隐藏变量的公式,在 LDA 中,隐藏变量即语料库中每个词语 \(w_{m,n}\) 对应的主题 \(z_{m,n}\)。对于参数集 \(\underline{\Theta}\) 和 \(\underline{\Phi}\),我们认为其只是马尔科夫链中稳定变量的统计学关联,会通过积分消去这些参数,这种策略在模型推理中被称为 “collapsed”,经常用于吉布斯推理之中。
基于上一节所述,推理的目标是 \(p(\vec{z}| \vec{w})\),其可以通过下式得到: \[ p(\vec{z} | \vec{w})=\frac{p(\vec{z}, \vec{w})}{p(\vec{w})}=\frac{\prod_{i=1}^{W} p\left(z_{i}, w_{i}\right)}{\prod_{i=1}^{W} \sum_{k=1}^{K} p\left(z_{i}=k, w_{i}\right)} \tag{62} \] 其中略去了超参数。该公式是难以直接求解的,需要引入吉布斯采样。为了模拟 \(p(\vec{z} | \vec{w})\),我们要基于 \((60)\) 推导单变量条件概率 \(p\left(z_{i} | \vec{z}_{-i}, \vec{w}\right)\).
联合概率分布
我们首先推导联合概率分布。在 LDA 中,联合概率分布可以拆分为两个部分: \[ p(\vec{w}, \vec{z} | \vec{\alpha}, \vec{\beta})=p(\vec{w} | \vec{z}, \vec{\beta}) p(\vec{z} | \vec{\alpha}) \tag{63} \] 上式利用了贝叶斯公式 \(P(A,B) = P(A|B)P(B)\),而因为第一项中 \(\vec{w}|\vec{z}\) 与 \(\vec{\alpha}\) 条件独立(\(\vec{w} \perp \vec{\alpha} | \vec{z}\),可通过贝叶斯球推导),而第二项中 \(\vec{z}\) 与 \(\vec{\beta}\) 独立。下面我们分别来推导第一项和第二项的概率。
第一项 \(p(\vec{w} | \vec{z})\) 可以通过给定相关联主题下的多项分布进行化简: \[ p(\vec{w} | \vec{z}, \underline{\Phi})=\prod_{i=1}^{W} p\left(w_{i} | z_{i}\right)=\prod_{i=1}^{W} \varphi_{z_{i}, w_{i}} \tag{64} \] 上式相当于进行了 \(W\) 次独立的多项试验(词袋模型不考虑词语间的顺序信息),我们可以进一步将其转换为一个遍历的乘积与一个遍历词表的乘积: \[ p(\vec{w} | \vec{z}, \underline{\Phi})=\prod_{k=1}^{K} \prod_{\left\{i: z_{i}=k\right\}} p\left(w_{i}=t | z_{i}=k\right)=\prod_{k=1}^{K} \prod_{t=1}^{V} \varphi_{k, t}^{n_{k}^{(t)}} \tag{65} \] 其中 \(n_{k}^{(t)}\) 表示词语 \(t\) 被观察到主题 \(k\) 的次数。基于上述公式,我们通过积分消去 \(\underline{\Phi}\),具体推导如下: \[ \begin{align*} p(\vec{w} | \vec{z}, \vec{\beta}) &=\int p(\vec{w} | \vec{z}, \underline{\Phi}) p(\underline{\Phi} | \vec{\beta}) \mathrm{d} \underline{\Phi} \tag{66}\\ &=\int \prod_{z=1}^{K} \frac{1}{\Delta(\vec{\beta})} \prod_{t=1}^{V} \varphi_{z, t}^{n_{z}^{(0)}+\beta_{t}-1} \mathrm{d} \vec{\varphi}_{z} \tag{67}\\ &=\prod_{z=1}^{K} \frac{\Delta(\vec{n}_{z}+\vec{\beta})}{\Delta(\vec{\beta})}, \quad \vec{n}_{z}=\{n_{z}^{(t)}\}_{t=1}^{V} \tag{68}\end{align*} \] 上式可以理解为 \(K\) 个狄利克雷-多项模型的乘积.(类比 \((52)\) 式)
与第一项类似,第二项主题分布 \(p(\vec{z} | \vec{\alpha})\) 可以表达为如下形式: \[ p(\vec{z} | \underline{\Theta})=\prod_{i=1}^{W} p\left(z_{i} | d_{i}\right)=\prod_{m=1}^{M} \prod_{k=1}^{K} p\left(z_{i}=k | d_{i}=m\right)=\prod_{m=1}^{M} \prod_{k=1}^{K} \vartheta_{m, k}^{n_{m}^{(k)}} \tag{69} \] 其中 \(d_i\) 表示词语 \(i\) 所属的文档,\(\boldsymbol{n}_{m}^{(k)}\) 表示文档 \(m\) 中主题 \(k\) 随词语出现的次数。对 \(\underline{\Theta}\) 积分,可以得到: \[ \begin{align*} p(\vec{z} | \vec{\alpha}) &=\int p(\vec{z} | \underline{\Theta}) p(\underline{\Theta} | \vec{\alpha}) \mathrm{d} \underline{\Theta} \tag{70}\\ &=\int \prod_{m=1}^{M} \frac{1}{\Delta(\vec{\alpha})} \prod_{k=1}^{K} \vartheta_{m, k}^{n_{m}^{(k)}+\alpha_{k}-1} \mathrm{d} \vec{\vartheta}_{m} \tag{71}\\ &=\prod_{m=1}^{M} \frac{\Delta\left(\vec{n}_{m}+\vec{\alpha}\right)}{\Delta(\vec{\alpha})}, \quad \vec{n}_{m}=\{n_{m}^{(k)}\}_{k=1}^{K} \tag{72}\end{align*} \] 综上所述,联合概率分布为: \[ p(\vec{z}, \vec{w} | \vec{\alpha}, \vec{\beta})=\prod_{z=1}^{K} \frac{\Delta(\vec{n}_{z}+\vec{\beta})}{\Delta(\vec{\beta})} \cdot \prod_{m=1}^{M} \frac{\Delta\left(\vec{n}_{m}+\vec{\alpha}\right)}{\Delta(\vec{\alpha})} \tag{73} \]
单变量条件分布
基于联合概率分布, 我们可以推导出一个词语的单变量条件分布,其下标为 \(i = (m,n)\),该分布即为吉布斯采样的更新公式,具体的推导过程如下: \[ \begin{align*} p\left(z_{i}=k | \vec{z}_{\neg i}, \vec{w}\right)&=\frac{p(\vec{w}, \vec{z})}{p\left(\vec{w}, \vec{z}_{\neg i}\right)}=\frac{p(\vec{w} | \vec{z})}{p\left(\vec{w}_{\neg i} | \vec{z}_{\neg i}\right) p\left(w_{i}\right)} \cdot \frac{p(\vec{z})}{p\left(\vec{z}_{\neg i}\right)} \tag{74} \\ & \propto\frac{\Delta(\vec{n}_{z}+\vec{\beta})}{\Delta(\vec{n}_{z,\neg i}+\vec{\beta})} \cdot \frac{\Delta(\vec{n}_{m}+\vec{\alpha})}{\Delta(\vec{n}_{m, \neg i}+\vec{\alpha})} \tag{75} \\ &= \frac{\Gamma(n_{k}^{(t)}+\beta_{t}) \Gamma(\sum_{t=1}^{V} n_{k,\neg i}^{(t)}+\beta_{t})}{\Gamma(n_{k,\neg i}^{(t)}+\beta_{t}) \Gamma(\sum_{t=1}^{V} n_{k}^{(t)}+\beta_{t})} \cdot \frac{\Gamma(n_{m}^{(k)}+\alpha_{k}) \Gamma(\sum_{k=1}^{K} n_{m, \neg i}^{(k)}+\alpha_{k})}{\Gamma(n_{m,\neg i}^{(k)}+\alpha_{k}) \Gamma(\sum_{k=1}^{K} n_{m}^{(k)}+\alpha_{k})} \tag{76} \\ &= \frac{n_{k,\neg{i}}^{(t)}+\beta_{t}}{\sum_{t=1}^{V} n_{k, \neg{i}}^{(t)}+\beta_{t}} \cdot \frac{n_{m,\neg{i}}^{(k)}+\alpha_{k}}{[\sum_{k=1}^{K} n_{m}^{(k)}+\alpha_{k}]-1} \tag{77} \\& \propto \frac{n_{k, \neg i}^{(t)}+\beta_{t}}{\sum_{t=1}^{V} n_{k, \neg i}^{(t)}+\beta_{t}}\left(n_{m, \neg i}^{(k)}+\alpha_{k}\right) \tag{78} \end{align*} \] 其中式 \((74)\) 利用了独立假设 \(w_{i} \perp z_{\neg i}\),并省略了常数项 \(p(w_i)\). 式 \((75)\) 只保留了词语 \(i\) 所属的主题与文档向量, 式 \((77)\) 省略了第二项的分母因为其与 \(k\) 无关。
多项参数
最后,我们需要找出对应马尔科夫链状态 \(\vec{z}\) 的多项参数集 \(\underline{\Theta}\) 和 \(\underline{\Phi}\). 基于共轭分布的性质和之前的推导结果,可以得到参数的如下后验分布: \[ \begin{align*}p(\vec{\vartheta}_{m} | \vec{z}_{m}, \vec{\alpha})&=\frac{1}{Z_{\theta_{m}}} \prod_{n=1}^{N_{m}} p(z_{m, n} | \vec{\vartheta}_{m}) \cdot p(\vec{\vartheta}_{m} | \vec{\alpha})=\operatorname{Dir}(\vec{\vartheta}_{m} | \vec{n}_{m}+\vec{\alpha}) \tag{79} \\ p(\vec{\varphi}_{k} | \vec{z}, \vec{w}, \vec{\beta}) &=\frac{1}{Z_{\varphi_{k}}} \prod_{[i: z_{i}=k]} p(w_{i} | \vec{\varphi}_{k}) \cdot p(\vec{\varphi}_{k} | \vec{\beta})=\operatorname{Dir}(\vec{\varphi}_{k} | \vec{n}_{k}+\vec{\beta}) \tag{80} \end{align*} \] 其中 \(\vec{n}_m\) 是文档 \(m\) 的主题观察数,\(\vec{n}_k\) 是主题 \(k\) 的词语观察数。使用狄利克雷分布的期望:\(\langle\operatorname{Dir}(d)\rangle= a_{i} / \sum_{i} a_{i}\),可以推导出参数的估计: \[ \begin{align*} \varphi_{k, t} &=\frac{n_{k}^{(t)}+\beta_{t}}{\sum_{t=1}^{V} n_{k}^{(t)}+\beta_{t}} \tag{81}\\ \vartheta_{m, k} &=\frac{n_{m}^{(k)}+\alpha_{k}}{\sum_{k=1}^{K} n_{m}^{(k)}+\alpha_{k}} \tag{82}\end{align*} \]
吉布斯采样算法
使用公式 \((78)\),\((81)\) 和 \((82)\),我们可以给出下图所示的吉布斯采样过程。关于采样的次数,有很多种准则,我们可以手动去确认聚类是否合理。关于模型参数的获取,一种方法是直接使用收敛后某次采样的数据计算,另一种方法是根据多次采样的结果求平均,注意求平均时每次采样会间隔 \(L\) 次迭代,来消除相邻马尔可夫状态之间的相关性。

LDA 超参数
在上一节中,我们假设超参数(狄利克雷分布的参数)是已知的,这些超参数对模型的行为有着重要影响。在 LDA 中,一般使用对称先验,即所有主题分配给一个文档的概率以及所有词语分配给一个主题的概率是一致的。本章节将对超参数的含义进行解释并给出基于数据估计超参数值的方法。
理解
狄利克雷超参数对多项参数一般具有平滑效应。通过减小 \(\alpha\) 和 \(\beta\) 的值,我们可以减少 LDA 中的这种平滑效应,产生更具决定性的主题关联,即 \(\underline{\Phi}\) 和 \(\underline{\Theta}\) 变得更加稀疏。
\(\underline{\Phi}\) 的稀疏性(由 \(\beta\) 控制)导致模型趋向于为每个主题分配更少的词语,这会进一步影响模型中主题的数量。对于稀疏的主题来说,如果主题数量 \(K\) 设置得较高,模型可能会拟合得更好,因为模型并不情愿为一个给定的词语分配多个主题。而 \(\underline{\Theta}\) 的稀疏性(由 \(\alpha\) 控制)导致模型趋向于使用较少的主题来描述文档(也会影响主题数量)。
上述理解表明超参数取值、主题数量与模型行为之间相互影响。根据已有经验,一个效果比较好的超参数取值为 \(\alpha = 50/ K\) 和 \(\beta = 0.01\)。我们也可以基于数据来估计超参数(给定主题数量 \(K\)),发现数据集中的具体特性。然而,对于超参数估计的解释并不简单,且其对于特定文档集的影响仍有待研究。下一节我们将给出对 \(\alpha\) 的估计(\(\theta\) 的估计类似)。
估计
估计超参数 \(\alpha\) 的方法有很多种,但这些方法都没有给出精确的闭合解,也不存在可直接进行贝叶斯推断(推断 \(\alpha\)) 的先验共轭分布。目前最准确的方法是迭代估计。我们将使用吉布斯采样器中已得到的信息(即关于主题的计数信息)来进行估计,参考式 \((52)\),通过最大似然估计迭代更新参数: \[ p(\mathcal{W} | \vec{\alpha}) =\frac{\Delta(\vec{n}+\vec{\alpha})}{\Delta(\vec{\alpha})}, \quad \vec{n}=\{n^{(v)}\}_{v=1}^{V} \tag{52} \] 对于无约束的向量化狄利克雷参数,一个简单的定点更新式的最大似然估计如下: \[ \alpha_{k} \leftarrow \frac{\alpha_{k}\left[\left(\sum_{m=1}^{M} \Psi\left(n_{m, k}+\alpha_{k}\right)\right)-M \Psi\left(\alpha_{k}\right)\right]}{\left[\sum_{m=1}^{M} \Psi\left(n_{m}+\sum_{k} \alpha_{k}\right)\right]-M \Psi\left(\sum_{k} \alpha_{k}\right)} \tag{83} \] 其中 \(\Psi(x)\) 是 digamma 函数,为 \(\log \Gamma(x)\)的导数。我们可以先基于某种方法初始化超参数,然后执行数次迭代直至收敛。
对于对称狄利克雷分布(LDA 中更常用),文献中并没有给出吉布斯采样器中这些超参数的估计方法,我们使用简单的 \(K\) 等分方式: \[ \alpha \leftarrow \frac{\alpha\left[\left(\sum_{m=1}^{M} \sum_{k=1}^{K} \Psi\left(n_{m, k}+\alpha\right)\right)-M K \Psi(\alpha)\right]}{K\left[\left(\sum_{m=1}^{M} \Psi\left(n_{m}+K \alpha\right)\right)-M \Psi(K \alpha)\right]} \tag{84} \] 除了上述最大似然估计,我们也可以考虑引入先验分布,通过最大后验分布估计或是 MCMC 方法来采样超参数。
分析主题模型
本节我们将使用给定语料库的潜在主题结构来:
- 分析新文档的主题结构
- 分析主题的聚类质量
- 基于主题推理新的关联(如文档或词语的相似性)
下面介绍 LDA 的几个实际应用场景。
Querying
给定一个文档,主题模型提供了两种方法来查询与其相似的文档:
- 通过文档参数的相似性分析
- 通过预测性的文档似然函数
上述两种方法都需要先给出查询文档的主题估计。
主题采样
对于一个查询文档,其由一个词语向量 \(\tilde{\vec{w}}\) 组成,我们将基于训练得到的 LDA 模型 \(\mathcal{M}\) 来采样主题,进而计算文档-主题分布参数 \(\tilde{\vec{\theta}}_m\).
采样的方式仍为吉布斯采样,对应于 \((78)\) 式,但需要注意的是主题-词语分布参数 \(\underline{\Phi}\) 和超参数 \(\alpha\) 来自于训练好的模型,我们只需要对新文档中的每个词语的主题进行采样(先随机分配主题),如下式所示: \[ p(\tilde{z}_{i}=k | \tilde{w}_{i}=t, \tilde{\vec{z}}_{\neg i}, \tilde{\vec{w}}_{\neg i} ; \mathcal{M}) \propto \varphi_{k, t}(n_{\tilde{m}, \neg i}^{(k)}+\alpha_{k}) \tag{85} \] 采样完成后,使用式 \((82)\) 来计算未知文档的主题分布: \[ \vartheta_{\tilde{m}, k} =\frac{n_{\tilde{m}}^{(k)}+\alpha_{k}}{\sum_{k=1}^{K} n_{\tilde{m}}^{(k)}+\alpha_{k}} \tag{86} \] 该采样同样适用于多篇文档。
相似性排序
得到了文档-主题分布 \(\vec{\vartheta}_{\tilde{m}}\) 后,我们可以使用两种方法来计算其与语料库中的文档-主题分布 \(\underline{\Theta}\) 的相似性。
第一种是 KL 散度,其基于两个离散变量定义: \[ D_{\mathrm{KL}}(X \| Y)=\sum_{n=1}^{N} p(X=n)\left[\log _{2} p(X=n)-\log _{2} p(Y=n)\right] \tag{87} \] KL 散度可以理解为交叉熵 \(H(X \| Y)=-\sum_{n} p(X=n) \log _{2} p(Y=n)\) 和 \(X\) 的熵 \(H(X)=-\sum_{n} p(X=n) \log _{2}p(X = n)\) 之间的差异,只有两个分布相同时, KL 散度才会为 0。
第二种方法是基于距离的测量(KL 散度不对称,无法度量距离),使用 Jensen-Shannon 距离: \[ D_{\mathrm{JS}}(X \| Y)=\frac{1}{2}\left[D_{\mathrm{KL}}(X \| M)+D_{\mathrm{KL}}(Y \| M)\right] \tag{88} \] 其中平均变量 \(M = \frac 1 2(X+Y)\).
预测性似然排序
另一种查询的方法是计算语料库中文档 \(m\) 可以基于查询文档 \(\tilde{m}\) 生成的可能性(仅考虑主题分布,不考虑具体词语),使用贝叶斯规则,可以得到下式: \[ \begin{align*} p(m | \tilde{m}) &=\sum_{k=1}^{K} p(m | z=k) p(z=k | \tilde{m}) \tag{89}\\ &=\sum_{k=1}^{K} \frac{p(z=k | m) p(m)}{p(z=k)} p(z=k | \tilde{m}) \tag{90}\\ &=\sum_{k=1}^{K} \vartheta_{m, k} \frac{n_{m}}{n_{k}} \vartheta_{\tilde{m}, k} \tag{91}\end{align*} \] 上式中假定 \(p(m) = n_m / W\) 和 \(p(z=k)=n_{k} / W\)。直观上看,式 \((91)\) 是一个主题向量间的加权标量乘积
,惩罚了短文档和强主题。
检索
对于上述基于主题模型的查询策略,我们可以将其应用于信息检索领域。关于检索效果的评估,最常用的评估指标是准确率和召回率。准确率是指所有检索返回的文档中相关文档的比例;而召回率则是指所有相关文档中被检索返回文档的比例。由于准确率 \(P\) 和召回率 \(R\) 通常相互制约,我们可以使用 \(F_{1}=2 P R /(P+R)\) 或加权值 \(F_{w}=\left(\lambda_{P}+\lambda_{R}\right) P R /\left(\lambda_{P} P+\lambda_{R} R\right)\) 来评价检索效果。
这里有两个问题需要说明,第一个是基于主题模型的检索可能或导致准确率的下降(对应于召回率的上升),因为其考虑了文档的潜在主题结构而非字面量。我们可以考虑将主题模型检索与其他检索方法进行结合。第二个是应当使用与主题分布相关的查询构造策略,如通过未知文档构造出的主题分布。
Clustering
LDA 还可以用于对文档与词语的聚类,其主题分布提供了一种软聚类的结果。基于主题分布,我们可以计算文档或主题之间的相似性(上一节所述)来查看聚类结果。
VI 距离评估
对聚类质量的评估也十分重要。原则上,我们可以直接基于计算得到的相似性来主观评价聚类质量,而一种更加客观的评估方法是将模型应用于已经分好类的语料库,比较模型给出的聚类结果与先验结果。下面我们将介绍一种比较聚类结果的方法,叫做 Variation of Information distance (VI 距离),其能够计算类数量不同的软聚类或硬聚类之间的距离。
VI 距离的计算公式如下:假定每个文档都有两种主题分布(软聚类):\(p(c=j | d_{m})\) 和 \(p(z=k | d_{m})\),其中主题 \(j \in [1,J]\) 和 \(k \in [1, K]\)。整个语料库上的主题分布取平均:\(p(c=j)=1 / M \sum_{m} p\left(c=j | d_{m}\right)\) 和 \(p(z=k)=1 / M \sum_{m} p\left(z=k | d_{m}\right)\).
对于相似的聚类,主题往往趋向于成对 \((c = j,z = k)\) 出现;而对于不相似的聚类,则对应于主题分布的相互独立:\(p(c=j, z=k)=p(c=j)p(z=k)\). 为了衡量相似程度,我们使用真实分布与假定独立的分布之间的 KL 散度,在信息论中这对应于随机变量 \(C\) 和 \(Z\) 之间的互信息: \[ \begin{align*} I(C, Z) &=D_{\mathrm{KL}}\{p(c, z) \| p(c) p(z)\} \\ &=\sum_{j=1}^{J} \sum_{k=1}^{K} p(c=j, z=k)\left[\log _{2} p(c=j, z=k)-\log _{2} p(c=j) p(z=k)\right] \tag{92} \end{align*} \] 其中联合分布 \(p(c=j,z=k) = \frac{1}{M} \sum_{m=1}^{M} p\left(c=j | d_{m}\right) p\left(z=k | d_{m}\right)\) . 只有两个变量间相互独立,其互信息才为 0。
进一步地,我们有 \(I(C, Z) \leq \min \{H(C), H(Z)\}\),其中 \(H(C)=-\sum_{j=1}^{J} p(c=j) \log _{2} p(c=j)\) 表示 \(C\) 的熵。当且仅当两个聚类相等时等号成立 \(I(C,Z) = H(C) = H(Z)\)。利用这一性质,我们定义 VI 距离的计算公式如下: \[ D_{\mathrm{VI}}(C, Z)=H(C)+H(Z)-2 I(C, Z) \tag{93} \] \(D_{\mathrm{VI}}(C, Z)\) 始终非负,且满足三角不等式:\(D_{\mathrm{VI}}(C, Z)+D_{\mathrm{VI}}(Z, X) \geq D_{\mathrm{VI}}(C, X)\)。VI 距离只取决于聚类情况,与数据本身的绝对数量不相关。
困惑度评估
除了上述基于先验结果的评估之外,我们还可以直接基于保留数据(即未参与模型训练的数据)的似然函数进行评估。然而似然值通常为较大的负数(对数函数特性),所以我们使用困惑度(perplexity)来作为评估标准: \[ \mathrm{P}(\tilde{\mathcal{W}} | \mathcal{M})=\exp -\frac{\sum_{m=1}^{M} \log p\left(\tilde{\vec{w}}_{\tilde{m}} | \mathcal{M}\right)}{\sum_{m=1}^{M} N_{m}} \tag{94} \] 困惑度可以直观地理解为模型生成测试数据所需要的均匀分布的词典大小。困惑度越低,表示模型对测试数据中词语的表示越好。对于 LDA,困惑度中似然函数的计算公式如下: \[ \begin{align*} p\left(\tilde{\vec{w}}_{\tilde{m}} | \mathcal{M}\right) &=\prod_{n=1}^{N_{\tilde{m}}} \sum_{k=1}^{K} p\left(w_{n}=t | z_{n}=k\right) \cdot p\left(z_{n}=k | d=\tilde{m}\right)=\prod_{t=1}^{V}\left(\sum_{k=1}^{K} \varphi_{k, t} \cdot \vartheta_{\tilde{m}, k}\right)^{n_{\tilde{m}}^{(t)}} \tag{95}\\ \log p\left(\tilde{\vec{w}}_{\tilde{m}} | \mathcal{M}\right) &=\sum_{t=1}^{V} n_{\tilde{m}}^{(t)} \log \left(\sum_{k=1}^{K} \varphi_{k, t} \cdot \vartheta_{\tilde{m}, k}\right) \tag{96}\end{align*} \] 其中 \(\vartheta_{\tilde{m}, k}\) 基于之前的 \((85)\) 式采样得到。
除了用于评估聚类质量,困惑度还可以用来判断吉布斯采样过程是否收敛。通过计算训练集的困惑度,我们可以了解模型是否存在过拟合,据此判断何时停止采样过程。