Trino 权威指南 Part 1
本篇博客是《Trino 权威指南》一书的学习笔记(Part 1)。
Trino 简介
Trino 是一种支持使用 SQL 访问任意数据源的 SQL 查询引擎,其能够提供更加灵活与高效的查询服务。本章节将简单介绍 Trino 的基本功能与使用场景。
大数据的问题
在如今的信息化时代,数据无处不在。无论是个人还是企业,对于数据的理解与洞察都是取得成功的关键。当前,对于数据的存储机制存在极强的多样性,例如关系型数据库、NoSQL 数据库、文档数据库、键值存储、对象存储,如下图所示。现代的信息系统通常需要将多种存储机制进行结合才能满足实际的使用需求。
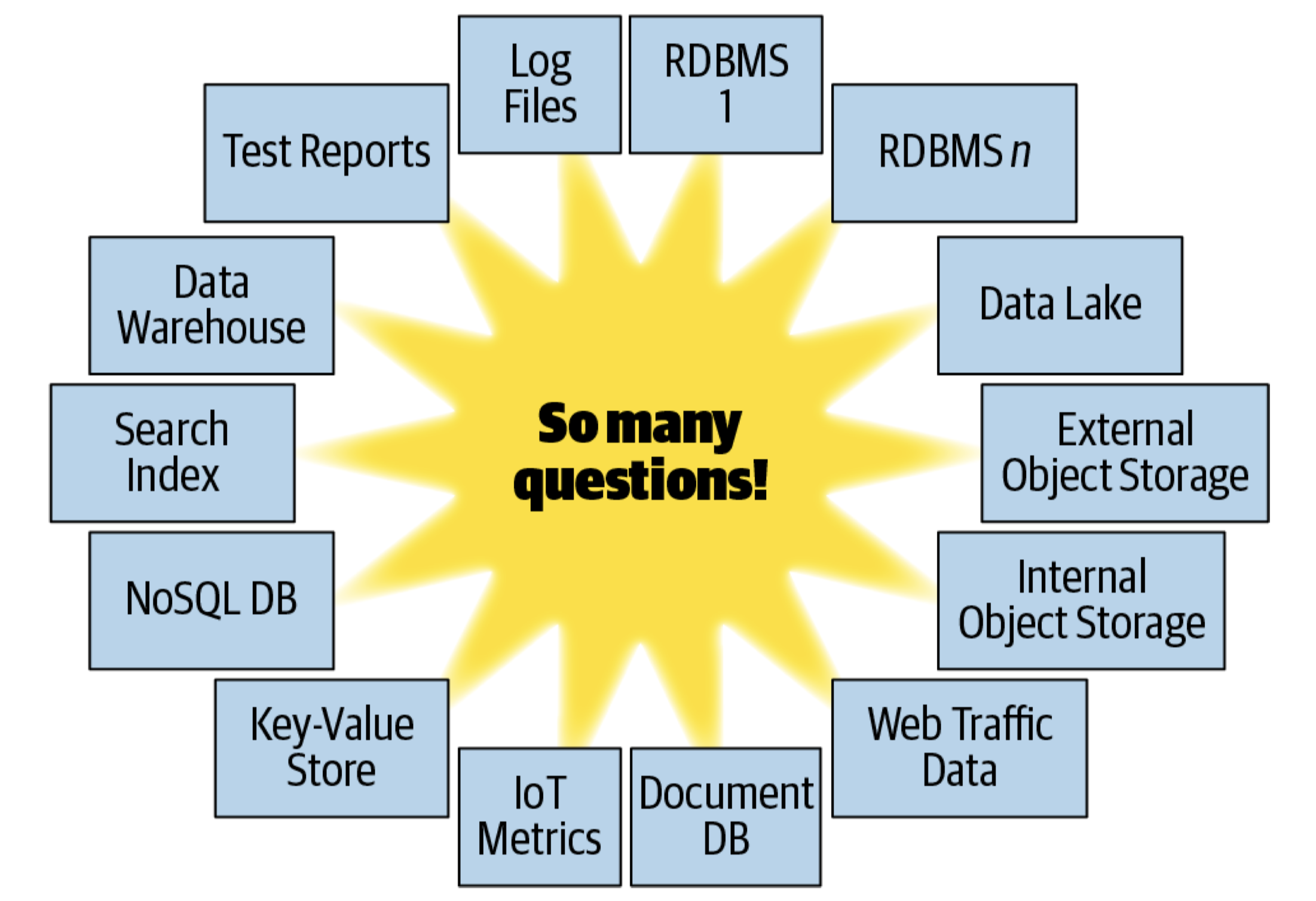
概括来说,上述这些不同的数据存储系统在数据查询方面存在着如下问题:
- 不同的系统使用不同的查询语言与分析工具,缺乏统一的标准工具(不同系统的 SQL 语法也存在差异)
- 不同系统的数据分布在不同的孤岛上,跨数据库的联邦查询支持还并不完善
- 传统的构建并维护大型数据仓库的方法成本过高,且步骤过于繁琐
为了解决以上问题,Trino 应运而生。
Trino 特性
Trino 是一个开源的分布式 SQL 查询引擎,能够通过联邦查询、并行查询、水平集群伸缩等方式解决上述问题。
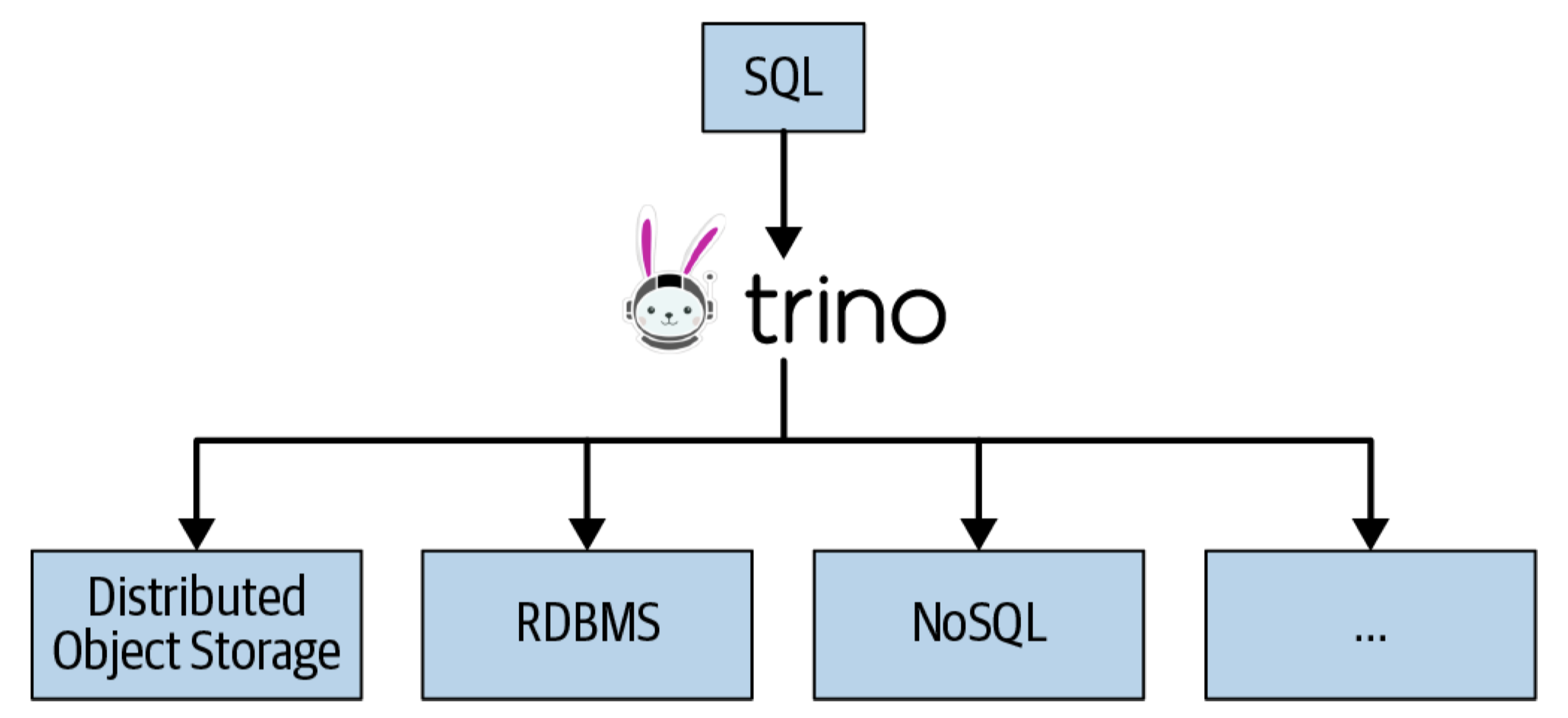
概括来说,Trino 具有以下三点特性:
- 专为性能与规模而设计
- 万物皆可 SQL
- 数据存储与查询计算资源隔离
Trino 使用场景
Trino 灵活而高效的特性使得用户可以自由地选择何时去使用 Trino,下面对 Trino 的一些典型使用场景进行了总结:
- 通过统一 SQL 访问各类数据源
- 执行多数据源联邦查询
- 执行 SQL 转换与 ETL
- 构建虚拟数仓(语义层)
- 构建数据湖查询引擎
Trino 安装与配置
本章节将简单介绍如何安装 Trino、配置数据源,以及查询数据。
基于 Docker
Trino 可以通过 Docker 进行安装,首先在本地安装 Docker,然后使用如下命令下载镜像(需要注册 Docker 个人用户):
$ docker pull trinodb/trino |
下载完成后,直接通过如下命令启动容器(不绑定对外端口的话无法访问 Web UI):
$ docker run -p 8080:8080 --name trino trinodb/trino |
启动成功后,可以连接容器进入 Trino CLI 测试是否安装成功(配置位于 /etc/trino 下):
$ docker exec -it trino trino |
基于文件
获取安装包
第二种方式是基于安装包文件进行安装,Trino 可以在 Linux 与 macOS 系统上运行,其需要 JVM 与 Python 的支持,具体版本为(针对 385 版本):
- Java 虚拟机:jdk 版本 11.0.11 或以上(可通过
java --version确认) - Python:版本 2.6 或以上(可通过
python --version确认)
在官网或 Maven 中心库下载最新或指定版本的 tar.gz 压缩包文件,并通过如下命令解压:
$ tar xvzf trino-server-*.tar.gz |
解压后的文件夹包含如下目录:
- lib:服务相关 jar 包及依赖
- plugins:相关插件及依赖
- bin:启动脚本
- etc:配置文件(用户创建)
- var:相关日志(服务创建)
添加配置文件
在启动 Trino 之前,还需要提供一系列配置文件,具体如下(本文基于 Trino 385 文档给出的参考配置):
节点属性
存储于 etc/node.properties 中,包含每个节点的配置信息。一个节点是 Trino 的单个安装实例,可参考的初始配置如下:
node.environment=demo |
node.environment表示节点的环境名称(只能包含小写字母或下划线)。同一集群的所有节点必须具有相同的环境名称node.id表示当前节点的唯一标识符(只能包含小写字母、下划线与横杠)- (可选)
node.data-dir可以任意配置日志的存储位置(注意文件夹权限)
JVM 配置
存储于 etc/jvm.config 中,Java 虚拟机启动的相关选项,可参考的配置如下:
-server |
配置属性
存储于 etc/config.properties 中,包含 Trino 服务的基本配置信息。每个 Trino 服务器可以作为 coordinator 或 worker 来执行功能。对于单节点机器来说,Trino 需同时作为 coordinator 与 worker,可参考的配置如下:
coordinator=true |
日志等级
存储于 etc/log.properties 中,属于可选配置,可以指定特定日志输出的最低等级:
io.trino=INFO |
日志默认输出 INFO 等级,上述语句将作用于 io.trino.server 与 io.trino.plugin.hive 两个类。
数据源配置
Trino 通过 catalogs 来定义用户可以使用的数据源。实际的数据访问通过 catalog 中所配置的 Trino 连接器(connector)来完成,连接器中将暴露数据源所有的 schema(库) 与 table(表)。
数据源存储于 etc/catalog 目录中,通过 xxx.properties 来指定特定的 catalog(名称匹配)。例如,我们可以创建文件 mysql.properties 来配置 MySQL 连接器:
connector.name=mysql |
每个 catalog 文件都需要 connector.name 属性,其他的属性取决于具体的连接器实现。
PS:对于 oracle 数据源,可能需要在 JVM 配置中添加时区设置 -Duser.timezone="+08:00"(针对 ORA-01882 报错)。
启动 Trino
添加好配置后,可以在安装文件夹下启动脚本:
$ bin/launcher run |
如果运行成功,将看到如下信息(实际上会打印出很多超多信息..):
INFO main io.trino.server.Server ======== SERVER STARTED |
也可以通过如下命令在后台启动 Trino(终端不输出信息):
$ bin/launcher start |
通过 stop 可以停止 Trino(前台启动的话直接退出即可)。
使用 Trino
本章节将介绍 Trino 的使用方式。
Trino 命令行接口
Trino 命令行工具需要单独下载(Docker 安装的话已经自动集成),在官网或 Maven 中心库下载 xxx-executable.jar 文件,然后将其重命名为 trino(后缀名也要去掉),并通过如下命令使其可执行:
$ chmod +x trino |
将该文件转移到 bin 文件夹下,配置路径后即可调用,MacOS 下可以修改 .zshrc 文件(修改为实际路径):
export PATH=~/bin/:$PATH |
现在即可在终端运行 Trino CLI:
$ trino --version |
如果直接使用的是本地测试或 docker 部署,可以直接启动 trino CLI,否则需要指定服务器地址:
$ trino --server https://trino.example.com:8080 |
启动成功后,可以直接编写 SQL 进行查询,注意需要以分号结尾:
trino> SELECT count(*) FROM tpch.tiny.nation; |
PS:如果有对网络进行过改动(例如连接我司办公网),Trino 可能会报 Failed communicating with server 的错误,Docker 下启动就没有这个问题。
Trino JDBC 驱动
Trino 还可以通过 JDBC 驱动在任意 Java 应用中访问,其是一种 Type 4 驱动,与 Trino 原生协议直接通信。下面以 Spring Boot 为例,介绍如何在常见的后端应用中引入 Trino。
首先通过 maven 引入相关 jar 包(要求 Jave 8 或以上),也可以下载 jar 包手动添加:
<dependency> |
引入驱动后,需要在配置文件中进行 Trino 的连接配置,下面给出的是 yaml 格式的配置示例:
spring: |
其中 jdbc-url 中可以额外去指定 catalog 与 schema 以限定数据源范围,user-name 无论是否执行认证都需要指定。
配置完成后,需要手动创建相关数据源配置(注意注解的名称不能与类名称重复):
|
执行调用时,可以通过自动装配的方式实现:
|
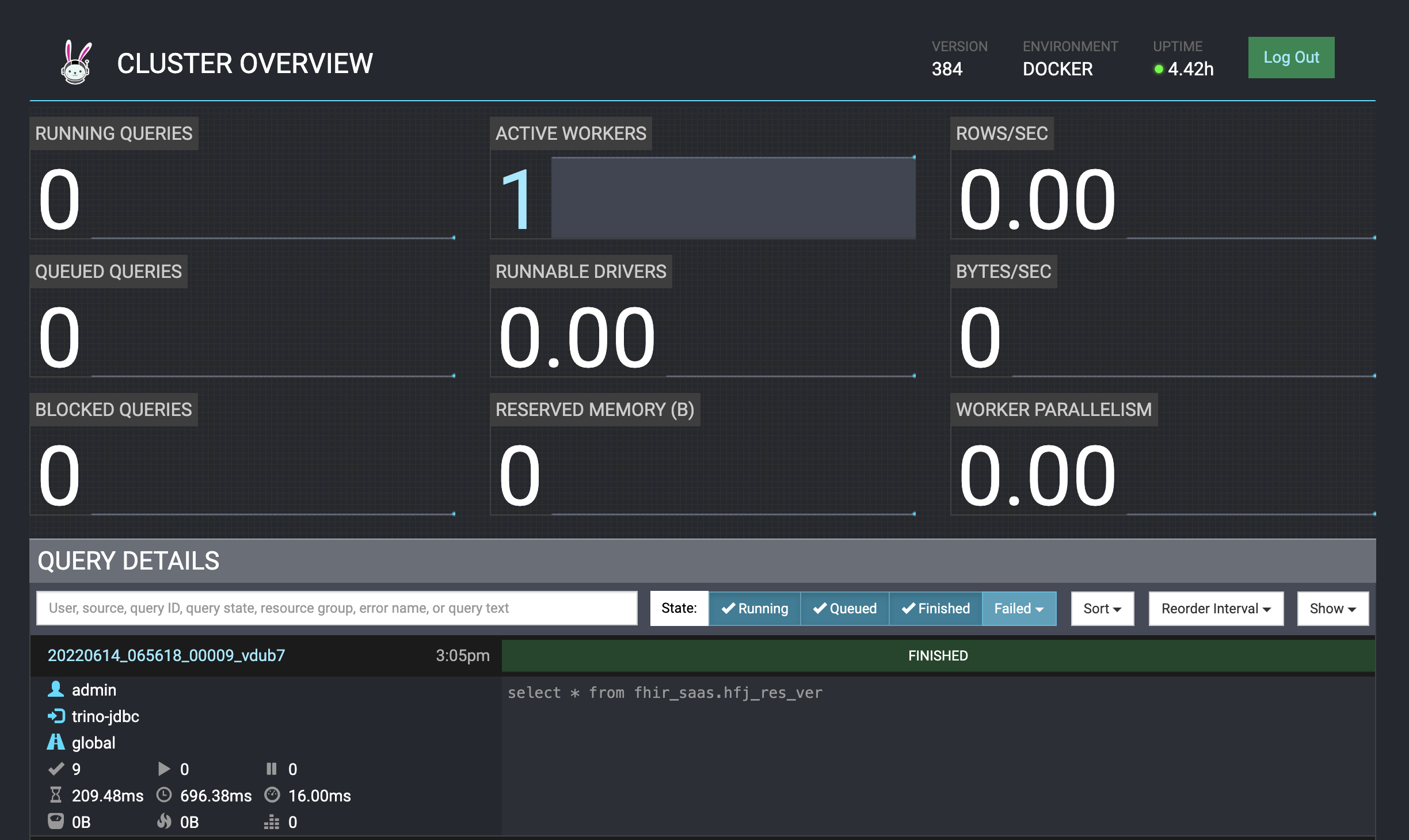
Trino Web UI
Trino 服务器提供了 Web UI 来监控 Trino 的相关信息,对于本地部署的 Trino,可以通过 http://localhost:8080 访问:
Trino SQL 概要
Trino 是一个遵循 ANSI SQL 的查询引擎,其在遵循标准的前提下引入了部分与其兼容的新特性。下面将对 Trino 中 SQL 的基础使用方法进行介绍。
概念
Trino 能够通过 SQL 访问任意的外部数据源,主要涉及以下四个概念:
- Connector:将 Trino 与数据源进行适配的连接器,每个数据源都需要关联到一个特定的连接器
- Catalog:定义访问某个数据源的具体细节,例如所包含的 schema 以及使用的连接器
- Schema:组织 table 的一种方式。catalog 和 schema 共同定义了可以被查询的 table 集合
- Table:无序行的集合,被组织为具有数据类型的命名列(比较拗口,其实就是表或者类似表的数据集合,不限于关系型数据库)
入门案例
首先可以通过如下语句查找所有数据源:
SHOW CATALOGS; |
然后可进一步查找特定数据源下的所有 schema:
SHOW SCHEMAS FROM tpch; |
再进一步查找特定 schema 下的所有 table:
SHOW TABLES FROM tpch.sf1; |
可以通过 DESCRIBE 查看 table 中的所有列:
DESCRIBE tpch.sf1.region; |
接下来,即可采用标准 SQL 来查询数据:
SELECT name FROM tpch.sf1.region; |
Trino 支持非常多的函数与操作符,可以在官方文档中进行查阅。
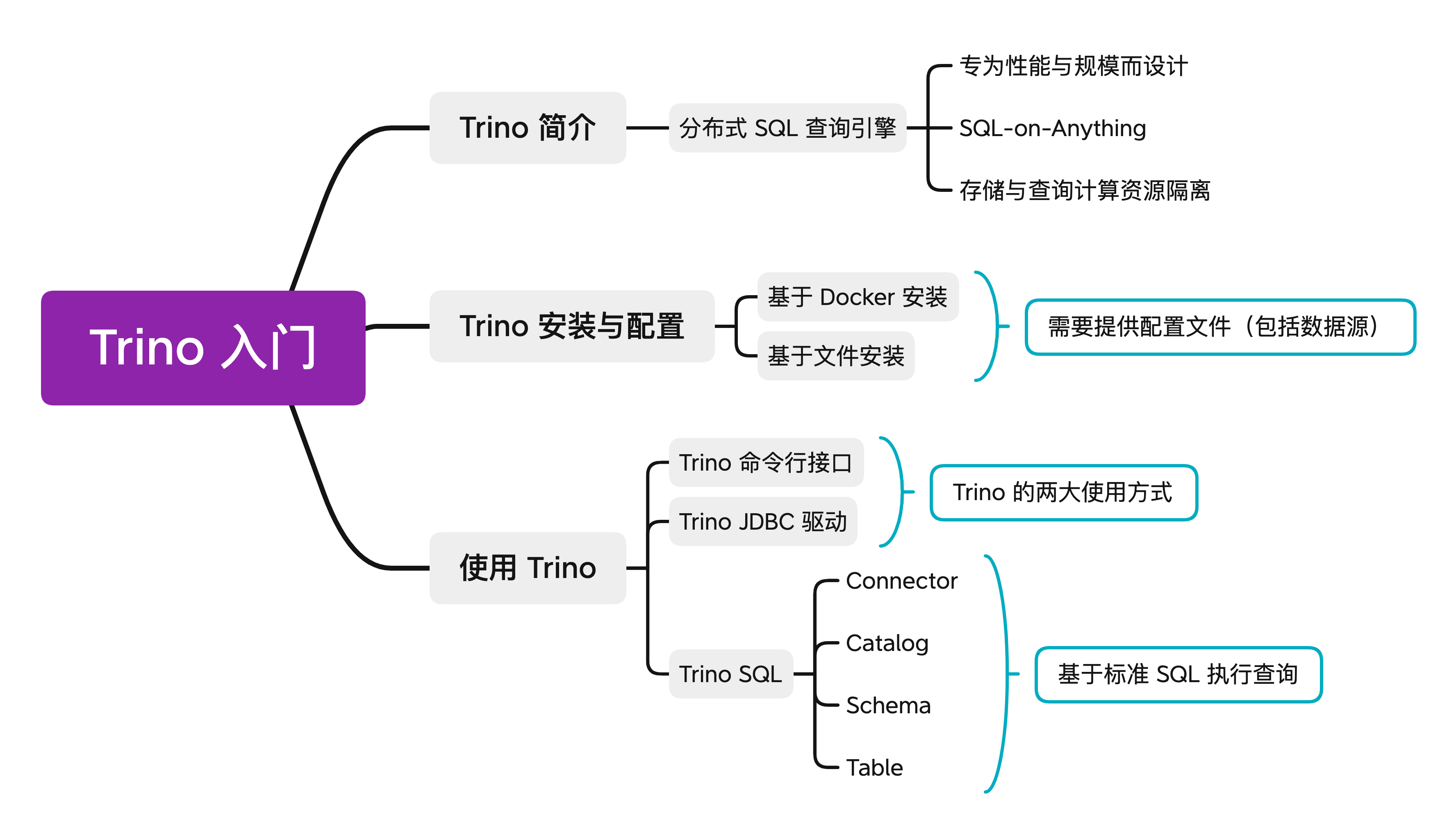
思维导图