本篇博客旨在对 OpenAI Gym 工具包的使用进行简单总结。
简介
这一部分参考官网提供的文档,对 Gym 的运作方式进行简单的介绍。Gym 是一个用于开发和比较强化学习算法的工具包,其对代理(agent)的结构不作要求,还可以和任意数值计算库兼容(如 Tensorflow 和 Pytorch)。Gym 提供了一系列用于交互的环境,这些环境共享统一的接口,以方便算法的编写。
环境
首先我们可以通过如下代码调用并展示(可视化)一个环境:
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())
env.close()
|
该代码创建了一个著名的 CartPole 环境,用于控制小车使上面的杆保持竖直不倒,如下图所示。在每一次迭代中,我们从动作空间中采样了一个随机动作(本环境中只有向左和向右两个动作)并执行。

执行代码后我们会发现,小车并不能如上图所示维持住平衡,而会直接滚出屏幕外。这是因为我们并没有根据环境的反馈而采取正确的动作。
观测
为了做出更加合适的动作,我们需要先了解环境的反馈。环境的 step 函数可以返回我们想要的值,其总共返回如下四个值:
observation(object):一个环境特定的对象以表示当前环境的观测状态,如相机的像素数据,机器人的关节角度和速度,桌游中的即时战况等reward(float):前一个动作所获得的奖励值,其范围往往随着环境的变化而各不相同,但目标一般都是提升总奖励值done(boolean):是否需要重置(reset)环境,不同的环境会有不同的终止条件,包括执行动作的次数限制、状态的变化阈值等info(dict):输出学习过程中的相关信息,一般用于调试
通过上述函数,我们可以实现经典的代理-环境循环,在每个时间步,代理选择一个动作,环境返回一个观察(状态)和一个奖励:
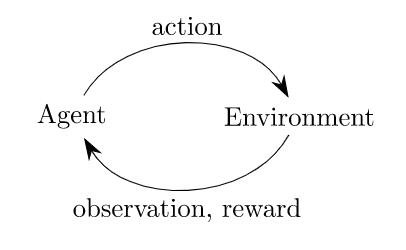
基于环境的反馈,我们可以对代码进行如下修改,达到终止条件时即退出循环:
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
|
在 CartPole 环境中,根据官方 wiki,观测状态有四维:小车位置、小车速度、杆的角度和杆顶端的速度(初始状态每个值均在 ±0.05 区间内取随机值);终止条件有三条:杆的角度大于 ±12 度,小车的位置超过 ±2.4,以及迭代次数超过 200(v1 为 500);每个步骤的奖励均为 1(包括终止步)。
空间
在 Gym 中,状态和动作都是通过 Space 类型来表示的,其可以定义连续或离散的子空间。最常用的两种 Space 是 Box 和 Discrete,在 CartPole 环境中状态空间和动作空间就分别对应这两种 Space:
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
print(env.observation_space)
|
Discrete 定义了一个从 0 开始取值的离散空间,而 Box 则可以表示一个 m*n 维的连续空间,需要为每个维度设置上下界。我们可以通过如下方式新建空间:
from gym import spaces
space = spaces.Discrete(8)
space_box_1 = Box(low=-1.0, high=2.0, shape=(3, 4), dtype=np.float32)
space_box_2 = Box(low=np.array([-1.0, -2.0]), high=np.array([2.0, 4.0]), dtype=np.float32)
|
除了上述两种空间外,Gym 还提供了一些其他的空间,包括多维离散空间、字典空间等,具体可以参考官方源码。
自定义环境
Gym 内置了许多强化学习的经典环境,包括经典控制、雅达利游戏、算法、机器人控制等。我们可以通过下述代码查看所有可以直接调用的环境:
from gym import envs
print(envs.registry.all())
|
但在实际应用中,面对一个全新的场景,我们往往需要自定义一个环境来训练我们的算法。本节将介绍如何自定义一个环境。
文件结构
根据官方说明,创建一个新的环境需要建立如下结构的 PIP 包:
gym-cdm/
├── README.md
├── setup.py
└── gym_cdm/
├── __init__.py
└── envs/
├── __init__.py
└── cdm_env.py
|
其中 gym-foo/setup.py 应包含如下代码:
from setuptools import setup
setup(name='gym_foo',
version='0.0.1',
install_requires=['gym']
)
|
gym-foo/gym-foo/__init__py 应包含如下代码:
from gym.envs.registration import register
register(
id='foo-v0',
entry_point='gym_foo.envs:FooEnv',
)
|
gym-foo/gym-foo/envs/__init__py 应包含如下代码:
from gym_foo.envs.foo_env import FooEnv
|
gym-foo/gym_foo/envs/foo_env.py 应包含如下代码:
import gym
from gym import error, spaces, utils
from gym.utils import seeding
class FooEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
...
def step(self, action):
...
def reset(self):
...
def render(self, mode='human'):
...
def close(self):
...
|
当全部定义完成后,我们可以在一级目录下通过 pip install -e . 来安装自定义环境(-e 表示本地可编辑的代码,可以快速更新改动),然后即可在程序中调用该环境:
import gym
import gym_foo
env = gym.make('foo-v0')
|
案例
下面通过经典的井字棋(Tic-Tac-Toe)游戏来说明环境的自定义方法。井字棋的玩法如下(就是简化版五子棋):

在井字棋环境中,状态即当前棋盘的局面,动作则是每一回合玩家的走棋。这里假定玩家为先手,电脑为后手。奖励基于玩家的胜负情况制定。具体代码如下:
class CdmEnv(gym.Env):
def __init__(self):
self.state = [['-' for _ in range(3)] for _ in range(3)]
self.counter = 0
self.done = 0
self.add = [0, 0]
self.reward = 0
def check(self):
if self.counter < 5:
return 0
for i in range(3):
if self.state[i][0] != '-' and self.state[i][1] == self.state[i][0] and self.state[i][1] == self.state[i][2]:
if self.state[i][0] == 'o':
return 1
else:
return 2
if self.state[0][i] != '-' and self.state[1][i] == self.state[0][i] and self.state[1][i] == self.state[2][i]:
if self.state[0][i] == 'o':
return 1
else:
return 2
if self.state[0][0] != '-' and self.state[1][1] == self.state[0][0] and self.state[1][1] == self.state[2][2]:
if self.state[0][0] == 'o':
return 1
else:
return 2
if self.state[0][2] != '-' and self.state[1][1] == self.state[0][2] and self.state[1][1] == self.state[2][0]:
if self.state[0][2] == 'o':
return 1
else:
return 2
return 0
def step(self, action):
x, y = action[0], action[1]
if self.done == 1:
print("游戏结束")
return [self.state, self.reward, self.done, self.add]
elif self.state[x][y] != '-':
print("非法步骤")
return [self.state, self.reward, self.done, self.add]
else:
if self.counter % 2 == 0:
self.state[x][y] = 'o'
else:
self.state[x][y] = 'x'
self.counter += 1
if self.counter == 9:
self.done = 1
win = self.check()
if win:
self.done = 1
print("玩家 ", win, " 号获胜", sep = '', end = '\n')
self.add[win - 1] = 1
if win == 1:
self.reward = 1
else:
self.reward = -1
return [self.state, self.reward, self.done, self.add]
def reset(self):
self.state = [['-' for _ in range(3)] for _ in range(3)]
self.counter = 0
self.done = 0
self.add = [0, 0]
self.reward = 0
return self.state
def render(self):
for i in range(3):
for j in range(3):
print(self.state[i][j], end = " ")
print("")
print("")
def getPosition(self, x, y):
item = self.state[x][y]
return item
def close(self):
print("env closed")
|
实际上,上述环境存在许多缺陷。首先是状态空间的表示,我们无法直接判断当前位置是否包含棋子,需要在 agent 中去记录,这显然是不合理的;其次是获胜条件与奖励函数的制定,我们希望环境不去区分玩家与电脑,而是针对每一步给出当前玩家应该受到的奖励。因此,可以考虑将奖励改为当前步下获胜以及防止下一步对方获胜的奖励,相应的胜负判断条件也需要进行修改。一个比较完善的代码(基于 Q 学习)可以参考这里。
以上就是 OpenAI Gym 的相关介绍及自定义环境的简单示范。