基于潜在结果框架的因果推断入门
本篇博客对基于潜在结果框架的因果推断理论进行了系统总结。
本文是一篇综述文章 A Survey on Causal Inference 的阅读笔记(大部分内容参照原文进行了较为通俗易懂的翻译,小部分内容加入了自己的理解)。
因果推断(Causal inference)是近年来很多领域的研究热点,诸如统计学、计算机科学、教育学、经济学等。和传统的试验性研究(如 RCT)相比,因果推断能够直接从观察性数据中估计因果关系,可以节省大量的人力物力成本。另一方面,得益于机器学习领域的发展,出现了各种各样用于因果估计的新方法。本文将对潜在结果框架(potential outcome framework)下的因果推断方法进行一个较为全面的综述。
背景
在日常生活中,我们可能会将相关关系和因果关系混为一谈,实际上两者存在着较大的差别。统计学中有一句名言:correlation does not imply causation(相关不代表因果)。相关关系描述的是两个变量相互关联,呈现出一个变量随另一个变量的变化而增加或减少的趋势;而因果关系则描述一个变量(因)导致了另一个变量(果)的变化,因对果(部分)负责,而果则(部分)取决于因。因果推断旨在基于已发生的结果推理出其中所存在的因果联系,与相关性推理相比,主要区别在于因果推断分析了在原因变量改变时(并不仅是简单的大小改变,而是包括类似有无这样的改变)结果变量的响应方式。
由于现实问题中因果的复杂性(并不是简单的一对一关系),学习因果是一个具有挑战性的问题。进行因果推断最有效的方式是进行随机对照试验(RCT),通过将参与者随机分配至对照组与试验组,并控制无关变量来观测目标干预的效果。然而,在实际中 RCT 通常成本较高,无法招募大量的参与者,难以代表整个干预的目标群体。此外,RCT 只关注样本的平均变化,并不能解释个体的干预效果,同时还可能存在伦理道德问题。因此,研究者们考虑直接基于观察性数据(observational data)来探究因果关系,观察性数据通常直接通过观测目标得出,没有对照与控制变量。我们可以从观察性数据中了解目标的行动、结果等信息,但是一般无法直接了解结果背后的原因,也就无法推导所谓的反事实结果(counterfactual outcome),从而无法把握其中的因果联系。
为了能够基于观察项数据进行因果推断,研究者们开发了各种因果推断框架,其中最著名的是潜在结果框架(potential outcome framework)以及结构因果模型(structual causal model),前者也被称为鲁宾因果模型(Rubin causal model)。潜在结果框架的主要目标是估计不同干预下的潜在结果(包括反事实结果),以估计实际的干预效果。而结构方程模型则是通过构建因果图与结构方程来探究因果关系。本文将介绍在潜在结果框架下的因果推断方法。关于结构因果模型的介绍可以参考这篇文章。
因果推断基础
定义
相关术语
对于潜在结果框架来说,其核心概念为单元、干预和结果。因果与干预绑定,作用于单元上,我们通过比较不同干预的潜在结果来估计干预效果。下面给出相关术语的详细定义。
定义 1:单元(Unit)。单元是干预效果研究中的最小研究对象。
一个单元可以是处于某个特定时间点的物体、公司、患者、个体或人群。在潜在结果框架下,不同时间点的单元是不同的。一个单元可以视作整个数据集的一个样本。
定义 2:干预(Treatment)。干预指作用于单元的动作。
令 \(W\left(W \in\left\{0,1,2, \ldots, N_{W}\right\}\right)\) 表示干预,其中 \(N_W+ 1\) 为可能干预的总数量。大部分研究都是针对二元干预,干预组(treated group)对应 \(W = 1\),对照组(control group)对应 \(W = 0\)。
定义 3:潜在结果(Potential outcome)。对于每个单元-干预对,将干预作用于该单元所得到的结果称为潜在结果。
值为 \(w\) 的干预的潜在结果定义为 \(Y(W= w)\)。
定义 4:观察结果(Observed outcome)。观察结果指实际执行了的干预所对应的结果。
观察结果也称为事实结果,记作 \(Y^F\)。潜在结果与观察结果的关系为 \(Y^{F}=Y(W=w)\),其中 \(w\) 为实际执行的干预。
定义 5:反事实结果(Counterfactual outcome)。反事实结果指相对于实际执行的干预,如果对单元执行了另一种干预所取得的结果。
反事实结果是除去实际执行的干预外的干预所对应的潜在结果。由于对一个单元(同一时间点)只能执行一种干预,因此只能观察到一个潜在结果,剩余的未观测潜在结果即为反事实结果。在多元干预场景下,定义值为 \(w'\) 的干预的反事实结果为 \(Y^{CF}(W =w')\);在二元干预场景下,为了简化标记,我们使用 \(Y^{CF}\) 定义反事实结果,\(Y^{C F}=Y(W=1-w)\),其中 \(w\) 为单元实际执行的干预。
在观察性数据中,除了执行的干预以及观察结果,单元的其他信息也有记录,我们可以将其分为预干预变量和后干预变量。
定义 6:预干预变量(Pre-treatment variables)。预干预变量指不会被干预影响的变量。
预干预变量也被称为背景变量(background variables),例如患者人口统计学,疾病史等。我们定义 \(X\) 为预干预变量。
定义 7:后干预变量(Post-treatment variables)。后干预变量指会被干预影响的变量。
后干预变量的一个例子就是中间结果,例如在药物试验中服药后的实验室检查结果。本文中除特殊说明外,均使用变量指代后干预变量。
干预效果
基于上述定义,我们可以对干预效果进行定量的描述。干预效果可以从多个层面进行度量,包括群体层面、干预组层面、亚组层面或是个体层面。这里给出二元干预下的干预效果定义。
在群体层面,干预效果称为平均干预效果(Average Treatment Effect, ATE),定义为: \[ \mathrm{ATE}=\mathbb{E}[\mathrm{Y}(W=1)-\mathrm{Y}(W=0)] \tag{1} \] 其中 \(\mathrm{Y}(W=1)\) 和 \(\mathrm{Y}(W=0)\) 分别表示整个群体的潜在干预结果与对照结果。
在干预组层面,干预效果被称为干预组的平均干预效果(Average Treatment Effect on the Treated group, ATT),定义为: \[ \mathrm{ATT}=\mathbb{E}[\mathrm{Y}(W=1)| W=1]-\mathbb{E}[\mathrm{Y}(W=0)| W=1] \tag{2} \] 其中 \(\mathrm{Y}(W=1)| W=1\) 和 \(\mathrm{Y}(W=0)| W=1\) 分别表示干预组的潜在干预结果与对照结果(添加了一个条件),类似地,对照组的平均干预效果被称为 ATC。
在亚组层面,干预效果被称为条件平均干预效果(Conditional Average Treatment Effect, CATE),定义为: \[ \mathrm{ CATE }=\mathbb{E}[\mathrm{Y}(W=1)|X=x]-\mathbb{E}[\mathrm{Y}(W=0)|X=x] \tag{3} \] 其中 \(\mathrm{Y}(W=1)| X=x\) 和 \(\mathrm{Y}(W=0)| X = x\) 分别表示背景变量 \(X = x\) 的亚组中的潜在干预结果与对照结果。当干预效果在不同的亚组中存在差异时,CATE 是一个常用的干预效果评估方法,也被称为异质干预效果。
在个体层面,干预效果被称为个体干预效果(Individual Treatment Effect, ITE),单元 \(i\) 的 ITE 定义为: \[ \mathrm{ITE}_{i}=Y_{i}(W=1)-Y_{i}(W=0) \tag{4} \] 其中 \(Y_{i}(W=1)\) 和 \(Y_{i}(W=0)\) 分别表示单元 \(i\) 的潜在干预结果与对照结果。某些文献中将 ITE 与 CATE 视作等价。
目标
对于因果推断,我们的目标是从观察性数据中估计干预效果。从形式上看,给定观察性数据集 \(\left\{X_{i}, W_{i}, Y_{i}^{F}\right\}_{i=1}^{N}\),其中 \(N\) 是数据集中的单元数量,则因果推断任务的目标是估计上述定义中的各项干预效果。
案例
为了更直观地进行说明,下面将给出一个医疗场景下的因果推断案例。我们希望去评估不同药物对于某种疾病的治疗效果。观察性数据(电子健康记录)包括患者人口统计学信息、患者所服用的具体药物与具体剂量,以及相关检查检验的结果。由于从数据中我们只能观察到特定患者的单个事实结果,因此我们的核心任务是预测如果对患者执行了另一种干预,会发生什么样的结果(即服用其他药物或调整药物剂量)。为了回答这一反事实问题,我们需要使用因果推断来预测每位患者的所有潜在结果。
需要特别注意的一点是,对于每种药物,其可能存在不同的剂量取值。例如,对于药物 A,其剂量范围是一个连续变量 \([a,b]\);而对于药物 B,其剂量范围则是一个离散变量,只有几个特定的取值。在本案例中,单元为患有待研究疾病的患者,干预则指用于该疾病的特定剂量的不同药物,我们使用 \(W\left(W \in\left\{0,1,2, \ldots, N_{W}\right\}\right)\) 来表示这些干预,例如,\(W_i = 1\) 表示单元 \(i\) 服用特定剂量的药物 A,\(W_i = 2\) 表示单元 \(i\) 服用特定剂量的药物 B。我们用 \(Y\) 来表示结果,例如可以衡量药物作用效果的血液检查。\(Y_i(W=1)\) 表示单元 \(i\) 服用特定剂量的药物 A 所产生的潜在结果。患者的特征包括年龄、性别、临床特征、检查检验结果等。在这些特征中,年龄、性别等人口统计学信息属于预干预变量,其不会被干预所影响;而部分临床特征与检查检验结果则会被干预(用药)所影响,属于后干预变量。在本例中,我们的目标是基于所提供的观察性数据估计不同药物(不同剂量)对于目标疾病的治疗效果。
假设
为了更好地估计干预效果,在因果推断中常常使用以下三种假设:
假设 1:稳定单元干预值假设(Stable Unit Treatment Value Assumption, SUTVA)。任意单元的潜在结果都不会因其他单元的干预发生改变而改变,且对于每个单元,其所接受的每种干预不存在不同的形式或版本,不会导致不同的潜在结果。
该假设强调了两点:第一点是每个单元之间的独立性,在上面的例子中,一名患者的结果不会影响另一名患者;第二点是每种干预只有一个版本,在上面的例子中,不同剂量的药物 A 对应于不同的干预。
假设 2:可忽略性假设(Ignorability)。给定背景变量 \(X\),干预的分配 \(W\) 独立于潜在结果,即 \(W \perp \!\!\! \perp Y(W=0), Y(W=1)|X\)。
在上面的例子中,可忽略性体现在两个方面:首先,如果两名患者具有相同的背景变量 \(X\),则无论采取怎样的干预措施,其潜在结果都会是相同的,即 \(p\left(Y_{i}(0), Y_{i}(1) | X=x, W=W_{i}\right)=p\left(Y_{j}(0), Y_{j}(1)| X=x, W=W_{j}\right)\);类似地,无论潜在结果如何,这两名患者的干预分配策略也会是相同的,即 \(p\left(W | X=x, Y_{i}(0), Y_{i}(1)\right)=p\left(W | X=x, Y_{j}(0), Y_{j}(1)\right)\) 。可忽略性也被称为无混淆假设(unconfoundedness),在该假设下,对于背景变量相同的单元,其干预分配可以视为随机的。
假设 3:正值假设(Positivity)。对于任意值的 \(X\),干预分配都不是确定的。
正值假设表示为公式即: \[ P(W=w |X=x)>0, \quad \forall w \text { and } x \tag{5} \] 如果对于某些 \(X\) 的值,干预分配是确定的,则对于这些值来说,至少有一项干预所导致的结果是无法被观测的,这样我们也就无法去估计干预的因果效应。在上面的例子中,假定有两种干预:药物 A 和药物 B,如果年龄大于 60 岁的患者总是给予药物 A,则我们就无法(也没有意义)去研究药物 B 在这些患者上的干预效果。换句话说,正值假设揭示的是干预的可变性,这对干预效果估计来说是十分重要的。
基于上述假设,观察结果与潜在结果之间的关系可以表示为: \[ \begin{aligned} \mathbb{E}[Y(W=w) | X=x] &=\mathbb{E}[Y(W=w) |W=w, X=x] \text { (Ignorability) } \\ &=\mathbb{E}\left[Y^{F}|W=w, X=x\right] \end{aligned} \tag{6} \]
上式中使用了可忽略性假设,其中 \(Y^F\) 是观察结果的随机变量,\(Y(W=w)\) 是干预 \(w\) 的潜在结果的随机变量。基于上式我们可以知道,如果我们对某一特定组(包括干预组、干预亚组等)的潜在结果感兴趣,可以通过该组的观察结果的期望对其潜在结果进行估计。
进一步地,基于上述等式,我们可以将 2.1 节中干预效果的相关定义表示为: \[ \begin{aligned} \mathrm{ITE}_{i} &=W_{i} Y_{i}^{F}-W_{i} Y_{i}^{C F}+\left(1-W_{i}\right) Y_{i}^{C F}-\left(1-W_{i}\right) Y_{i}^{F} \\ \mathrm{ATE} &=\mathbb{E}_{X}\left[\mathbb{E}[Y^{F} | W=1, X=x\right]-\mathbb{E}\left[Y^{F} | W=0, X=x]\right] \\ &=\frac{1}{N} \sum_{i}\left(Y_{i}(W=1)-Y_{i}(W=0)\right)=\frac{1}{N} \sum_{i} \mathrm{ITE}_{i} \\ \mathrm{ATT} &=\mathbb{E}_{X_{T}}\left[\mathbb{E}[Y^{F} | W=1, X=x]-\mathbb{E}[Y^{F} | W=0, X=x]\right] \\ &=\frac{1}{N_{T}} \sum_{\left\{i: W_{i}=1\right\}}\left(Y_{i}(W=1)-Y_{i}(W=0)\right)=\frac{1}{N_{T}} \sum_{\left\{i: W_{i}=1\right\}} \operatorname{ITE}_{i} \\ \text { CATE } &=\mathbb{E}[Y^{F} | W=1, X=x]-\mathbb{E}[Y^{F} | W=0, X=x] \\ &=\frac{1}{N_{x}} \sum_{\left\{i: X_{i}=x\right\}}\left(Y_{i}(W=1)-Y_{i}(W=0)\right)=\frac{1}{N_{x}} \sum_{\left\{i: X_{i}=x\right\}} \operatorname{ITE}_{i} \end{aligned} \tag{7} \] 其中 \(Y_{i}(W=1)\) 和 \(Y_{i}(W=0)\) 是单元 \(i\) 的潜在干预与对照结果,\(N\) 是整个群体的单元数量,\(N_T\) 是对照组中的单元数量,\(N_x\) 是 \(X = x\) 的亚组中的单元数量。对于 \(\mathrm{ITE}_{i}\) ,上述公式将不同的干预值进行了合并,如 \(W_i = 1\) 时,\(\mathrm{ITE}_{i} = Y_{i}^{F}-Y_{i}^{C F}\) ;而对于 \(\mathrm{ATE}, \mathrm{ATT}, \mathrm{CATE}\),上式首先基于期望公式与 \((6)\) 式将其表示为与观察结果相关的等式,然后使用期望的估计方法进行进一步地转化,最终都表示为了基于不同组别的 \(\mathrm{ITE}\) 的均值。
然而,由于我们无法同时观测到一个单元的潜在干预结果与对照结果,因此干预效果估计的关键在于,如何估计 \(\mathrm{ITE}\) 中的反事实结果,即估计 \(\frac{1}{N_{*}} \sum_{i} Y_{i}(W=1)\) 和 \(\frac{1}{N_{u}} \sum_{i} Y_{i}(W=0)\),其中 \(N_{\star}\) 指 \(N, N_T\) 或 \(N_x\)。在下一节中,我们将介绍进行估计时所面临的挑战以及一般的解决方法。
混杂因子及一般解法
如上所述,因果推断的核心即估计在一个特定组别上的平均潜在干预结果与对照结果。以 \(\mathrm{ATE}\) 为例,我们考虑直接使用观测到的干预与对照结果进行平均,即 \(\hat{\mathrm{ATE}}=\frac{1}{N_{T}} \sum_{i=1}^{N_{T}} Y_{i}^{F}-\frac{1}{N_{C}} \sum_{i=1}^{N_{C}} Y_{j}^{F}\),其中 \(N_T\) 和 \(N_C\) 分别是干预组与对照组的单元数量。然而,由于混杂因子的存在,上述估计(针对观察性数据)往往存在严重的问题,可能会包含完全虚假的因果效应。
定义 8:混杂因子(Confounders)。混杂因子是会同时影响干预分配以及结果的变量。
混杂因子是一些特殊的预干预变量(即背景变量),当直接计算观测到的干预与对照结果的平均值时,所得出的 \(\mathrm{ATE}\) 不仅包括了干预对结果的影响,还包括了混杂因子对结果的影响,从而导致了伪效应(spurious effect)的出现。在上面的例子中,患者年龄就是一个混杂因子。年龄影响着康复率:一般来说,年轻患者要比老年患者恢复地更好;年龄同时还影响着干预的而选择:年轻的患者可能趋向于使用药物 A 而老年患者趋向于使用药物 B,或者年轻患者使用药物的剂量与老年患者存在差异。下表给出了对应的观察性数据:
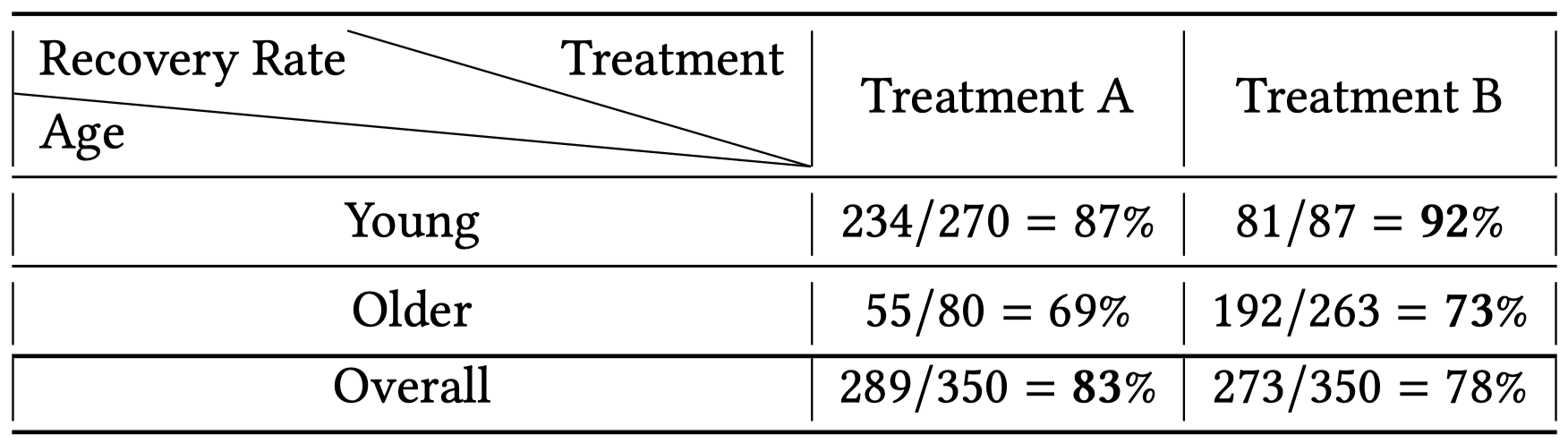
基于该数据得到的伪 \(\mathrm{ATE}\) 为: \[ \hat{\mathrm{ATE}}=\frac{1}{N_{A}} \sum_{i=1}^{N_{A}} Y_{i}^{F}-\frac{1}{N_{B}} \sum_{i=1}^{N_{B}} Y_{j}^{F}=\frac {289} {350} -\frac {273} {350}=5 \% \] 其中 \(N_A\) 和 \(N_B\) 分别表示使用药物 A 和 B 的患者的数量。然而,我们并不能得出干预 A 要优于干预 B 的结论,因为采取干预 A 的组的平均康复率高的原因可能是该组中大部分的患者都是年轻患者(350 名中的 270 名),年龄对康复率的影响(伪效应)导致了计算得出的因果效应并不具有可靠性。
另一方面,上表中还存在着一个有趣的现象:辛普森悖论(Simpson's paradox)。具体来说,在年轻患者与老年患者对应的组别中,药物 B 都比药物 A 有着更好的康复率;然而当把这两组结合到一起后,药物 A 的总平均康复率却要高于药物 B。导致这一悖论的罪魁祸首依旧是混杂因子,当比较整个组的康复率时,药物 A 对应的组中大部分人都是年轻患者,表格中给出的比较并不能消除年龄对康复率的影响。
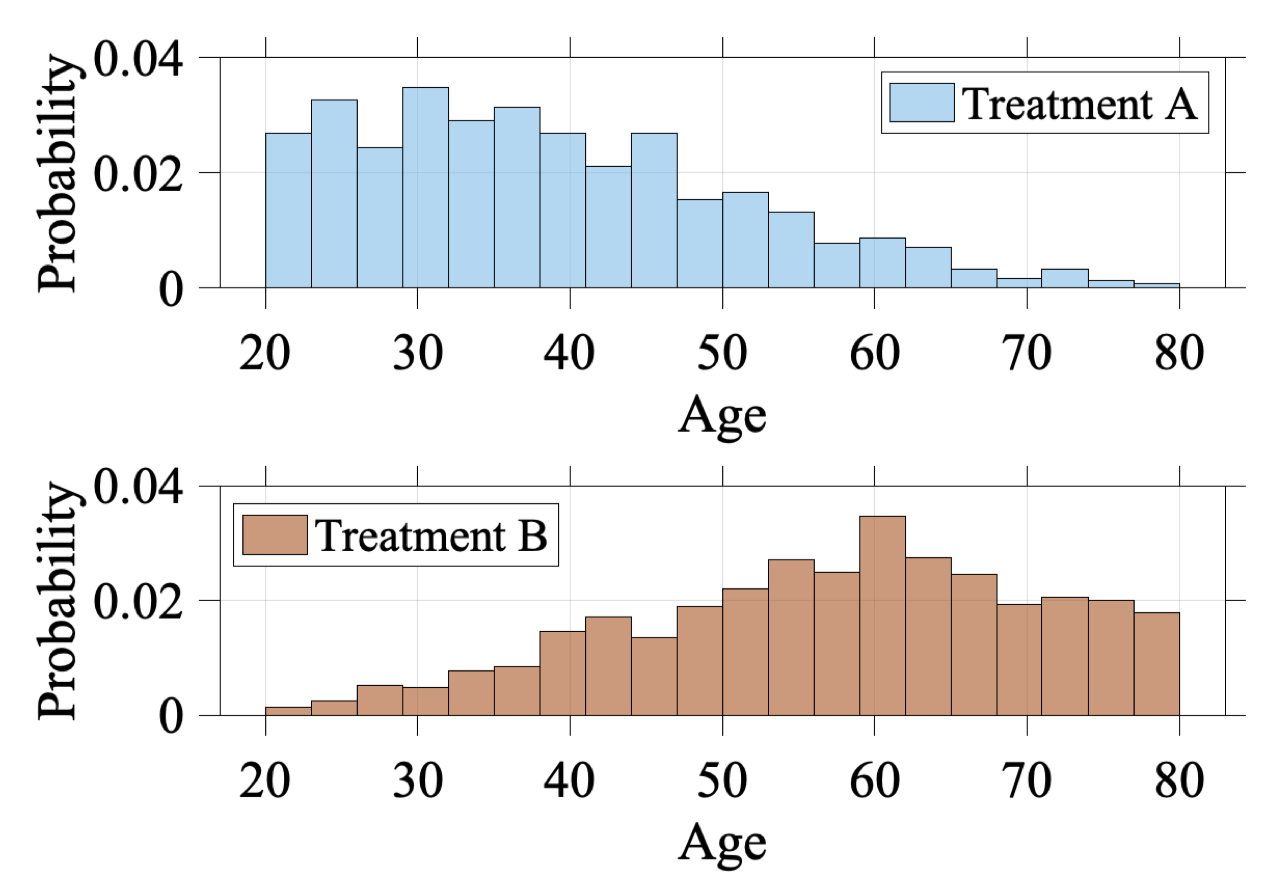
除了对干预效果估计带来的伪效应,混杂因子还会导致选择偏差(selection bias),从而使得反事实结果的估计变得困难。选择偏差描述的现象是:观测到的组别中的分布并不能代表我们感兴趣的组别,即 \(p\left(X_{o b s}\right) \neq p\left(X_{*}\right)\)。混杂因子会影响单元的干预选择,从而导致选择偏差的出现。在上面的例子中,年龄是一个混杂因子,因此不同年龄的患者有着不同的干预偏好。下图展示了观测到的干预组与对照组的年龄分布。显而易见,观察干预组的年龄分布于观察对照组的年龄分布存在着差异。这一现象使得反事实结果的估计变得更加困难,因为我们需要去基于观察对照组来估计干预组中单元的对照结果,以及基于观察干预组来估计对照组中单元的干预结果。如果我们不对选择偏差进行处理,直接基于 \(W = w\) 的数据训练潜在结果估计模型 \(\hat{Y}(x, w)=f_{w}(x)\),则训练得到的模型对于实际接受的干预不为 \(w\) 的单元的潜在结果估计的效果会很差。这一问题在机器学习领域也被称为协变量偏移(covariate shift)。
处理混杂因子带来的问题(伪效应与选择偏差)是因果推断领域的关键研究问题,我们将处理混杂因子变量的过程称为调整混杂因子(adjust confounders)。下面将简要介绍处理上述两个问题的通用性方案(个人观点:两个问题之间存在关联,选择偏差是根本,可以引发伪效应),注意这些方案需要基于三种基本假设,特别是可忽略性假设,即不存在未观测的混杂因子。
对于伪效应问题,我们应该将混杂因子变量所造成的结果纳入到计算中去。一般来说,我们可以先估计以混杂因子变量为条件的干预效果,然后基于混杂因子的分布进行加权平均,具体来说: \[ \begin{aligned} \hat{\mathrm{ATE}} &=\sum_{x} p(x) \mathbb{E}[Y^{F} |X=x, W=1]-\sum_{x} p(x) \mathbb{E}[Y^{F} | X=x, W=0] \\ &=\sum_{\mathcal{X}^{*}} p\left(X \in \mathcal{X}^{*}\right)\left(\frac{1}{N_{\left\{i: X_{i} \in \mathcal{X}^{*}, W_{i}=1\right\}}} \sum_{\left\{i: X_{i} \in \mathcal{X}^{*}, W_{i}=1\right\}} Y_{i}^{F}\right)-\sum_{\mathcal{X}^{*}} p\left(X \in \mathcal{X}^{*}\right)\left(\frac{1}{N_{\left\{j: X_{j} \in \mathcal{X}^{*}, W_{j}=0\right\}}} \sum_{\left\{j: X_{j} \in \mathcal{X}^{*}, W_{j}=0\right\}} Y_{j}^{F}\right) \end{aligned} \tag{8} \] 其中 \(\mathcal{X}^{*}\) 是 \(X\) 的值的集合,\(p\left(X \in \mathcal{X}^{*}\right)\) 是位于 \(\mathcal{X}^{*}\) 中的背景变量在整个群体上的概率,\(\left\{i: X_{i} \in \mathcal{X}^{*}, W_{i}=w\right\}\) 是背景变量值(相同值)属于 \(\mathcal{X}^*\) 且干预为 \(w\) 的单元亚组。这一方案的代表性方法是分层(Stratification),将在之后进行介绍。
对于选择偏差问题,我们一般有两种解决方案:第一种方案通过创造一个拟群(pseudo group)来近似目标组的真实分布。常用的方法包括样本重加权、匹配、基于树的方法、混杂因子平衡、平衡表征学习方法、基于多任务的方法等。创建的拟群可以缓解选择偏差的消极影响,从而得到更加可靠的反事实结果估计。第二种方案首先仅基于观察性数据训练基础的潜在结果估计模型,然后对选择偏差引起的估计偏差进行纠正。这种方案的代表性方法是基于元学习的方法。
基于假设的因果推断方法
在本章节中,我们将介绍基于之前所述的三种假设的因果推断方法。根据其对混杂因子的处理方式,可以将其分为如下几类:
- 重加权方法(Re-weighting methods)
- 分层方法(Stratification methods)
- 匹配方法(Matching methods)
- 基于树的方法(Tree-based methods)
- 基于表征的方法(Representation based methods)
- 多任务方法(Multi-task methods)
- 元学习方法(Meta-learning methods)
下面将分别对这些方法进行详细介绍。PS:个人认为第三部分原文描述得相当精炼,如果对其中涉及的算法没有一定的了解很容易晕掉,这里尝试去理解了原作者想表达的核心内容,省略了原文的部分描述,建议对于感兴趣的算法去阅读相应的原始论文。
重加权方法
由于混杂因子的存在,干预组与对照组中协变量(注意混杂因子只是协变量的一种,而协变量是背景变量的一种,这里可以将这三个概念暂时等价)的分布是不同的,这会导致选择偏差的出现,换句话说也就是干预的分配与观察性数据中的协变量相关。样本重加权是一种解决选择偏差的高效方法,通过为每个单元分配合适的权重,创建出一个干预组与对照组分布类似的拟群。
在样本重加权方法中,一个关键的概念是平衡分数(balancing score)。平衡分数 \(b(x)\) 是一种通用的权重分数,其是 \(x\) 的函数且满足:\(W \perp \!\!\! \perp x \mid b(x)\),其中 \(W\) 是干预分配而 \(x\) 是背景变量。平衡分数的设计方法有很多种,最常规的是 \(b(x) = x\)。倾向评分是平衡分数的一个特例,其定义如下:
定义 9:倾向评分(Propensity score)。倾向评分是给定背景变量时干预的条件概率:
\[ e(x)=\operatorname{Pr}(W=1 | X=x) \tag{9} \]
倾向评分可以表明在给定一个观测协变量集合的情况下,单元被分配到特定干预的概率。基于倾向评分的重加权方法是目前最常见的一种手段。下图对本节涉及到的重加权方法进行了归类,我们将先介绍仅基于样本重加权的方法,然后介绍同时对样本与协变量进行重加权的方法。
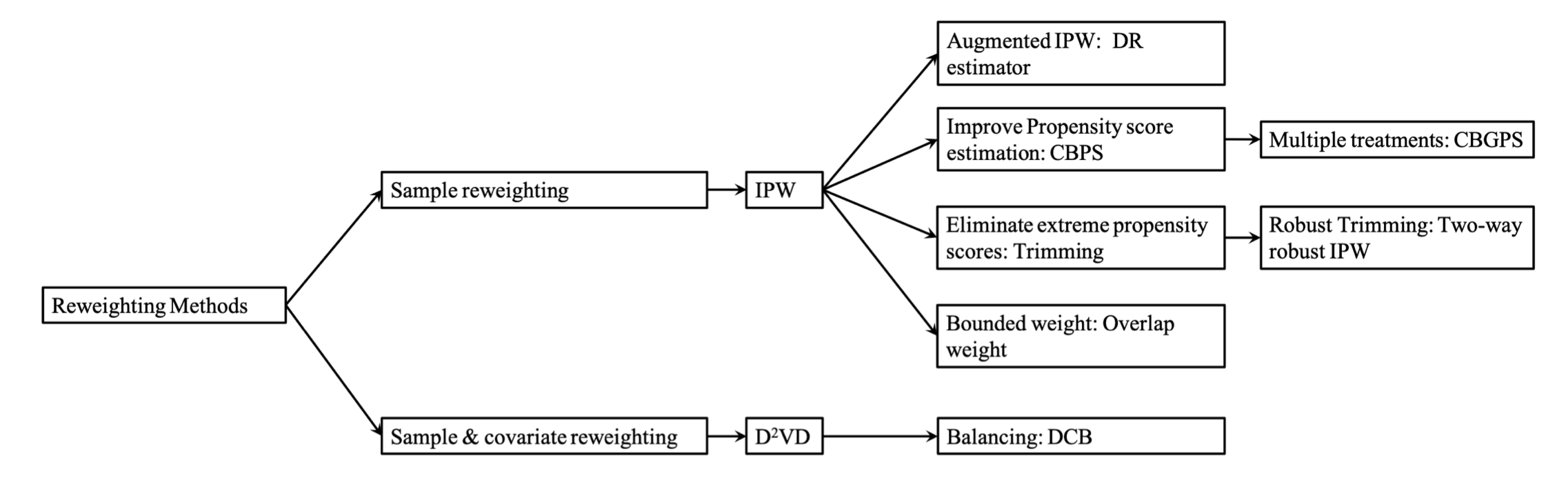
基于倾向评分的样本重加权
仅基于样本重加权的代表性方法是逆倾向加权(IPW),也被称为逆概率干预加权(IPTW),其为每个样本分配一个权重 \(r\): \[ r=\frac{W}{e(x)}+\frac{1-W}{1-e(x)} \tag{10} \] 其中 \(W\) 是干预分配(二元),\(e(x)\) 是 \((9)\) 式中定义的倾向评分。重加权后的 ATE 的计算公式如下: \[ \hat{\mathrm{ATE}}_{IPW}=\frac{1}{n} \sum_{i=1}^{n} \frac{W_{i} Y_{i}^{F}}{\hat{e}\left(x_{i}\right)}-\frac{1}{n} \sum_{i=1}^{n} \frac{\left(1-W_{i}\right) Y_{i}^{F}}{1-\hat{e}\left(x_{i}\right)} \tag{11} \] 上式的归一化形式如下(当倾向评分通过估计获得时使用): \[ \hat{\mathrm{ATE}}_{I P W}=\sum_{i=1}^{n} \frac{W_{i} Y_{i}^{F}}{\hat{e}\left(x_{i}\right)} / \sum_{i=1}^{n} \frac{W_{i}}{\hat{e}\left(x_{i}\right)}-\sum_{i=1}^{n} \frac{\left(1-W_{i}\right) Y_{i}^{F}}{1-\hat{e}\left(x_{i}\right)} / \frac{\left(1-W_{i}\right)}{1-\hat{e}\left(x_{i}\right)} \tag{12} \] 研究表明,无论在大规模样本还是小规模样本中,倾向评分都能够平衡协变量所带来的选择偏差。我们可以进一步将倾向评分与匹配、分层、回归等方法相结合,以消除协变量的影响。
然而,在实践中,IPW 估计器的正确性高度依赖于倾向评分估计的正确性,倾向评分的轻微错误会导致 ATE 的较大偏差。为了解决这一问题,研究人员提出了双重稳健估计器(DR),也被称为加强 IPW(AIPW)。DR 估计器将倾向评分加权与结果回归相结合,可以保证即使部分评分或回归不正确(不能同时不正确),估计器仍具有鲁棒性。DR 估计器的具体公式如下: \[ \begin{aligned} \hat{\mathrm{ATE}}_{D R} &=\frac{1}{n} \sum_{i=1}^{n}\left\{\left[\frac{W_{i} Y_{i}^{F}}{\hat{e}\left(x_{i}\right)}-\frac{W_{i}-\hat{e}\left(x_{i}\right)}{\hat{e}\left(x_{i}\right)} \hat{m}\left(1, x_{i}\right)\right]-\left[\frac{\left(1-W_{i}\right) Y_{i}^{F}}{1-\hat{e}\left(x_{i}\right)}-\frac{W_{i}-\hat{e}\left(x_{i}\right)}{1-\hat{e}\left(x_{i}\right)} \hat{m}\left(0, x_{i}\right)\right]\right\} \\ &=\frac{1}{n} \sum_{i=1}^{n}\left\{\hat{m}\left(1, x_{i}\right)+\frac{W_{i}\left(Y_{i}^{F}-\hat{m}\left(1, x_{i}\right)\right)}{\hat{e}\left(x_{i}\right)}-\hat{m}\left(0, x_{i}\right)-\frac{\left(1-W_{i}\right)\left(Y_{i}^{F}-\hat{m}\left(0, x_{i}\right)\right)}{1-\hat{e}\left(x_{i}\right)}\right\} \end{aligned} \tag{13} \] 其中 \(\hat{m}\left(1, x_{i}\right)\) 和 \(\hat{m}\left(0, x_{i}\right)\) 分别为干预与对照结果的回归模型估计。只要倾向评分或模型能够正确地解释结果中混杂因子与变量之间的关系,DR 估计器就可以给出稳定且无偏的结果。
另一种改善 IPW 估计器的方法是提升倾向评分估计的正确性。在 IPW 估计器中,倾向评分同时作为干预概率与协变量的平衡分数而出现,为了利用倾向评分的这一双重特性,研究人员提出了协变量平衡倾向评分(CBPS),其通过解决如下问题来估计倾向评分: \[ \mathbb{E}\left[\frac{W_{i} \tilde{x_{i}}}{e\left(x_{i} ; \beta\right)}-\frac{\left(1-W_{i}\right) \tilde{x_{i}}}{1-e\left(x_{i} ; \beta\right)}\right]=0 \tag{14} \] 其中 \(\tilde{x_{i}}=f\left(x_{i}\right)\) 是预定义的 \(x_i\) 的向量化度量函数。通过求解上述问题,CBPS 可以直接根据估计的参数化倾向评分计算协变量平衡分数,从而提升倾向评分模型的鲁棒性,减少错误的发生。CBPS 的一种扩展是协变量平衡广义倾向评分(CBGPS),其能够处理连续值的干预。对于连续值干预来说,很难直接去最小化干预组与对照组之间的协变量分布距离,CBGPS 通过弱化平衡分数的定义来解决这一问题。基于原始定义,干预分配需要条件独立于背景变量,而 CBGPS 则选择将加权后的干预分配与协变量之间的相关性最小化(相比独立来说要求变低了)。具体来说,CBGPS 的目标是学习一个基于倾向评分的权重,使得干预分配与协变量之间加权后的相关性最小,如下式所示: \[ \begin{aligned} \mathbb{E}\left(\frac{p\left(t^{*}\right)}{p\left(t^{*} | x^{*}\right)} t^{*} x^{*}\right) &=\int\left\{\int \frac{p\left(t^{*}\right)}{p\left(t^{*} | x^{*}\right)} t^{*} d P\left(t^{*} |x^{*}\right)\right\} x^{*} d P\left(x^{*}\right) \\ &=\mathbb{E}\left(t^{*}\right) \mathbb{E}\left(x^{*}\right)=0 \end{aligned} \tag{15} \] 其中 \(p\left(t^{*} | x^{*}\right)\) 是倾向评分,\(\frac{p\left(t^{*}\right)}{p\left(t^{*} | x^{*}\right)}\) 是平衡权重,\(t^{*}\) 和 \(x^{*}\) 是归一化后的干预分配与背景变量。总的来说,CBPS 和 CBGPS 都直接面向协变量平衡的目标来学习基于倾向评分的样本权重,这样可以避免倾向评分模型的错误带来的负面效果。
上述改进方法主要针对的是 IPW 估计器中倾向评分的正确性问题,IPW 估计器的另一个缺陷是当估计的倾向评分较小时,估计器可能会不稳定。具体来说,如果任意一项干预分配的可能性较小,则用于估计倾向评分的逻辑回归模型可能会在尾部附近不稳定,从而导致 IPW 估计器的不稳定。为了解决这个问题,一种常规的解决方式是进行修整(trimming),其可以视为一种正则化方法,通过预定义一个阈值,去除倾向评分小于该阈值的样本来提升估计器的稳定性。然而,研究表明这种方法对修整的阈值高度敏感,同时较小的倾向评分结合修整的过程可能会导致 IPW 估计器中出现不同的非高斯渐近分布。基于这些问题,研究者们提出了一种双向鲁棒性 IPW 估计方法(two-way robustness IPW estimation),这种方法将子采样与基于局部多项式回归的修整偏差校正器相结合,对于较小的倾向评分与较大的修整阈值均具有鲁棒性。另一种克服小倾向评分下 IPW 不稳定性的替代性方案是重新设计样本权重,研究者们提出了一种重叠权重(overlap weight),其中每个单元的权重与该单元分配到对立组的概率成比例。具体来说,重叠权重 \(h(x)\) 定义为 \(h(x) \propto 1-e(x)\),其中 \(e(x)\) 是倾向评分。重叠权重的大小被限制在区间 \([0,0.5]\) 以内,因此它对较小的倾向评分并不敏感。研究表明在所有的平衡权重中,重叠权重具有最小的渐近方差。
混杂因子平衡
对于上述的样本重加权方法来说,其中所有的观察变量都被视为混杂因子。然而实际上,并不是所有的观察变量都是混杂因子,有些变量可能是只影响结果的调整变量(adjustment variables),有些则可能是无关变量(irrelevant variables)。下图给出了关于混杂因子与调整变量的区别说明(这里并没有考虑到仅影响干预分配的工具变量以及介于干预与结果之间的中介变量):
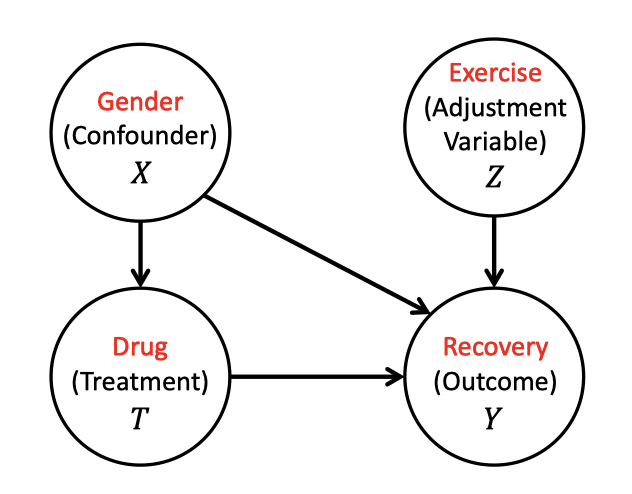
为了区分混杂因子与调整变量的不同影响,同时消除无关变量,研究者们提出了一种数据驱动的可变性分解算法(Data-Driven Variable Decomposition),调整后的结果通过下式给出: \[ Y_{\mathrm{D}^{2} \mathrm{VD}}^{*}=\left(Y^{F}-\phi(\mathbf{z})\right) \frac{W-p(x)}{p(x)(1-p(x))} \tag{16} \] 其中 \(\mathbf{z}\) 是调整变量。因此,\(\mathrm{D}^{2} \mathrm{VD}\) 算法的 ATE 估计公式为: \[ \mathrm{ATE}_{\mathrm{D}^{2} \mathrm{VD}}=\mathbb{E}\left[\left(Y^{F}-\phi(\mathbf{z})\right) \frac{W-p(x)}{p(x)(1-p(x))}\right] \tag{17} \] 为了求解 \(\mathrm{ATE}_{\mathrm{D}^{2} \mathrm{VD}}\),需要基于所有的观察变量对 \(Y_{\mathrm{D}^{2} \mathrm{VD}}^{*}\) 进行回归分析。该分析的目标函数是 \(Y_{\mathrm{D}^{2} \mathrm{VD}}^{*}\) 与所有观察变量的线性回归函数的 \(l_2\) 损失,以及用于区分混杂因子、调整变量与无关变量的稀疏正则项(注意这里本质上还是人工区分)。然而,在实践中通常缺少关于观察变量的先验知识,同时数据通常是高维且包含噪声的。为了解决这一问题,研究者们又提出了差分混杂因子平衡(DCB)算法来从高维数据中选择并区分混杂因子,然后通过对样本与混杂因子同时进行重加权来平衡分布。
分层方法
分层方法,也称为子分类(subclassification)或区组(blocking),是混杂因子调整的代表性方法。分层方法的核心思想是将整个组划分为同质性的亚组(区组)来调整干预组与对照组之间的偏差。理想情况下,在每个亚组中,干预组和对照组的协变量的分布是类似的,因此来自相同亚组的单元可以近似看作是从随机对照试验数据中进行采样获得的。基于每个亚组的同质性,每个亚组内的干预效应(即 CATE)可以通过面向 RCT 数据的方法进行计算。在计算出每个亚组的 CATE 后,目标组的干预效应可以通过将属于该组的亚组的 CATE 结合起来得到(参考 \((8)\) 式)。以计算 ATE 为例,如果我们将整个数据集分为 \(J\) 个区组,则 ATE 可以通过下式进行估计: \[ \mathrm{ATE}_{\mathrm{strat}}=\hat{\tau}^{\mathrm{strat}}=\sum_{j=1}^{J} q(j)\left[\bar{Y}_{t}(j)-\bar{Y}_{c}(j)\right] \tag{18} \] 其中 \(\bar{Y}_{t}(j)\) 和 \(\bar{Y}_{c}(j)\) 分别是在第 \(j\) 个区组中干预结果与对照结果的平均。\(q(j)=\frac{N(j)}{N}\) 是第 \(j\) 个区组中单元数量与单元总数的比值。
与普通的差分 ATE 估计器(\(\mathrm{ATE}_{\mathrm{diff}}=\hat{\tau}^{d i f f} = \frac{1}{N_{T}} \sum_{i=1}^{N_{T}} Y_{i}^{F}-\frac{1}{N_{C}} \sum_{i=1}^{N_{C}} Y_{j}^{F}\))相比(这里原文似乎公式有误),分层方法可以有效地减少 ATE 估计的偏差。具体来说,假定结果与协变量线性相关:\(\mathbb{E}\left[Y_{i}(w)|X_{i}=x\right]=\alpha+\tau * w+\beta * x\),则普通差分估计器的偏差为: \[ \mathbb{E}\left[\hat{\tau}^{\mathrm{diff}}-\tau|X, W\right]=\left(\bar{X}_{t}-\bar{X}_{c}\right) \beta \tag{19} \] 而分层估计器的偏差为区组内偏差的加权平均: \[ \mathbb{E}\left[\hat{\tau}^{\mathrm{strat}}-\tau |X, W\right]=\left(\sum_{j=1}^{J} q(j)\left(\bar{X}_{t}(j)-\bar{X}_{c}(j)\right)\right) \beta \tag{20} \] 与差分估计器相比,分层估计器对于每个协变量减少的偏差为: \[ \gamma_{k}=\frac{\sum_{j} q(j)\left(\bar{X}_{t, k}(j)-\bar{X}_{c, k}(j)\right)}{\bar{X}_{t, k}-\bar{X}_{c, k}} \tag{21} \] 上式中 \(\bar{X}_{t, k}(j)\left(\bar{X}_{c, k}(j)\right)\) 是第 k 个协变量在第 j 个区组中的干预组(对照组)的均值,而 \(\bar{X}_{t, k}\left(\bar{X}_{c, k}\right)\) 是整个干预(对照)组中第 k 个协变量的均值。
分层方法的关键部分就是如何创建区组以及如何将创建的区组结合在一起。创建区组的一种常用方法是相等频率法(equal frequency),该方法基于出现的概率(如倾向评分)进行区组的划分,使得每个亚组(区组)中的协变量具有相同的出现概率。如 \((18)\) 式所示,ATE 可以通过每个区组的 CATE 的加权平均求得,权重与区组中的单元数量相关。然而,由于区组中干预组与对照组的重叠性可能不足(倾向评分差异较大导致被划分到不同的组),这种方法可能会存在较高的方差。为了减少这种方差,可以考虑对基于倾向评分划分的区组通过区组特定的干预结果的逆方差进行重加权,不过这种方法虽然可以减少方差,但同时会不可避免地增加估计偏差。
上述划分区组的方法均是基于预干预变量(即背景变量)的,而在某些实际的应用中,可能需要基于某些后干预变量比较结果,记作 \(S\)。举例来说,在疾病发展的过程中的某些标记物(如艾滋病中的 CD4 数量)可以视作一种后干预变量,其受到干预的影响。在比较艾滋病患者药物治疗效果的研究中,研究人员可能对 CD4 数量小于 200 个/立方毫米的组的治疗效果感兴趣。然而,如果直接比较 \(S^{obs}<200\) 的组中的观察结果可能并不会得到真实的结果,因为该组的两个亚组 \(\left\{i: W_{i}=1, S^{o b s}<200\right\}\) 与 \(\left\{j: W_{j}=0, S^{o b s}<200\right\}\) 将存在较大的差异(因为干预对后干预变量的值有影响)。我们可以通过原则分层(principle stratification)来解决这个问题,其基于后干预变量的潜在值来构建亚组。我们定义 \(S(W=w)\) 为干预值 w 下后干预变量的值,基于 \(S\) 的潜在值独立于干预分配的假设,一个亚组的干预效果可以通过比较其对应的干预与对照集合的结果得出:\(\left\{Y_{i}^{o b s}: W_{i}=1, S_{i}\left(W_{i}=1\right)=v_{1}, S_{i}\left(W_{i}=0\right)=v_{2}\right\}\) 和 \(\left\{Y_{j}^{o b s}: W_{j}=0, S_{j}\left(W_{j}=1\right)=v_{1}, S_{j}\left(W_{j}=0\right)=v_{2}\right\}\),其中 \(v_1\) 和 \(v_2\) 是该亚组中两个后干预变量的值。通过这种方式可以保证两个集合的相似性,以得到真实的干预效应。
匹配方法
如之前所述,缺少反事实结果与混杂因子偏差是干预效果分析中的两大关键挑战。基于匹配的方法提供了一种估计反事实结果的方式,同时还能够减少混杂因子带来的偏差。一般来说,通过匹配方法给出第 \(i\) 个单元的潜在结果为: \[ \hat{Y}_{i}(0)=\left\{\begin{array}{ll} Y_{i} & \text { if } W_{i}=0, \\ \frac{1}{\# \mathcal{J}(i)} \sum_{l \in \mathcal{J}(i)} Y_{l} & \text { if } W_{i}=1 ; \end{array} \quad \hat{Y}_{i}(1)=\left\{\begin{array}{ll} \frac{1}{\# \mathcal{J}(i)} \sum_{l \in \mathcal{J}(i)} Y_{l} & \text { if } W_{i}=0, \\ Y_{i} & \text { if } W_{i}=1; \end{array}\right.\right. \tag{22} \] 其中 \(\hat{Y}_{i}(0)\) 和 \(\hat{Y}_{i}(1)\) 是估计的对照与干预结果,\(\mathcal{J}(i)\) 是单元 \(i\) 的相反组中的匹配邻居。
对匹配样本的分析实际上是一种 RCT 的模仿:在 RCT 中,理想情况下干预组与对照组中协变量的分布是类似的,因此我们可以直接比较两个组之间的结果。匹配方法也是基于这样的思想来减少或消除混杂因子的影响。
距离度量
我们可以通过多种距离来衡量单元之间的接近程度,例如常用的欧式距离与马氏距离。很多的匹配方法都设计了其独有的距离度量,可以将其统一抽象为:\(D\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\left\|f\left(\mathbf{x}_{i}\right)-f\left(\mathbf{x}_{j}\right)\right\|_{2}\),这些距离度量的主要区别在于转换函数 \(f(\cdot)\) 的设计,下面将介绍几种常见的设计。
基于倾向评分的转换函数
首先,可以直接基于表示协变量的倾向评分来计算两个单元间的相似度:\(D\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\left|e_{i}-e_{j}\right|\),其中 \(e_{i}\) 和 \(e_{j}\) 分别是单元 \(\mathbf{x}_{i}\) 和 \(\mathbf{x}_{j}\) ($ $ 对应该单元的所有协变量)的倾向评分。其次,还可以使用线性倾向评分进行距离度量:\(D\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\left|\operatorname{logit}\left(e_{i}\right)-\operatorname{logit}\left(e_{j}\right)\right|\),这种方法可以有效地减少偏差。进一步地,还可以将倾向评分度量与其他距离度量方法结合起来,进行基于多重准则的比较。例如可以先基于倾向评分筛选较为相似的单元,然后进一步基于某些关键协变量的相似度进一步筛选。
其他转换函数
基于倾向评分的转换函数只考虑了协变量的信息,下面介绍一些利用了结果信息的距离度量方法。第一种方法是基于预后评分(prognosis score)的度量,即估计的对照结果(先基于协变量进行估计)。转换函数可以表示为:\(f(x)=\hat{Y}_{c}\)。预后评分的表现依赖于对照结果与协变量之间关系的建模,且并没有考虑到干预结果。第二种方法是基于希尔伯特-施密特独立性标准的最近邻匹配(HSIC-NNM),其通过学习两个线性的映射分别用于对照结果估计任务与干预结果估计任务,来克服预后评分的不足之处。具体来说,线性映射的参数通过最大化映射子空间与结果的非线性依赖来学习得到:\(M_{w}=\arg \max _{M_{w}} \operatorname{HSIC}\left(\mathbf{X}_{w} M_{w}, Y_{w}^{F}\right)-\mathcal{R}\left(M_{w}\right)\),其中 \(w=0,1\) 分别代表对照组与干预组,\(\mathbf{X}_{w} M_{w}\) 是转换后的子空间(即估计结果),\(Y_{w}^F\) 是观测到的对照/干预结果,\(\mathcal{R}\) 是避免过拟合的正则化参数。上述目标函数可以确保学习到的转换函数将原始协变量投影到了一个相似的单元会具有相似结果的信息子空间中。
与基于倾向评分的距离度量方法聚焦于平衡相比,预后评分与 HSIC-NNM 聚焦于表示观测结果与转换空间关系的表示。还有一些研究尝试将上述两类方法结合在一起,例如平衡非线性表示方法(BNR)。BNR 方法将协变量映射到一个平衡的低维度空间,其中非线性变换函数的参数通过联合优化下述两个目标实现:最大化非连续类散点与类内部散点之间的差异,这样具有相同结果预测的单元会在转换后具有相似的表示;最小化转换后的对照组与干预组之间的最大平均差异,以便在转换后获得平衡的空间。此外,还有一些研究使用了类似的目标函数但不同的正则化,例如使用条件性生成对抗网络来确保转换函数屏蔽了干预分配信息。
上述方法均将一种或两种转换分别作用于干预组与对照组,不同于这些方法,随机性最近邻匹配(RNNM)方法采用一系列的线性映射作为转换函数,并通过基于每个转换子空间的最近邻匹配得到的中位数干预效果作为估计干预效果。该方法的理论依据是 JL 引理,其保证了高维空间的点的成对相似性信息可以通过随机线性映射来保护。
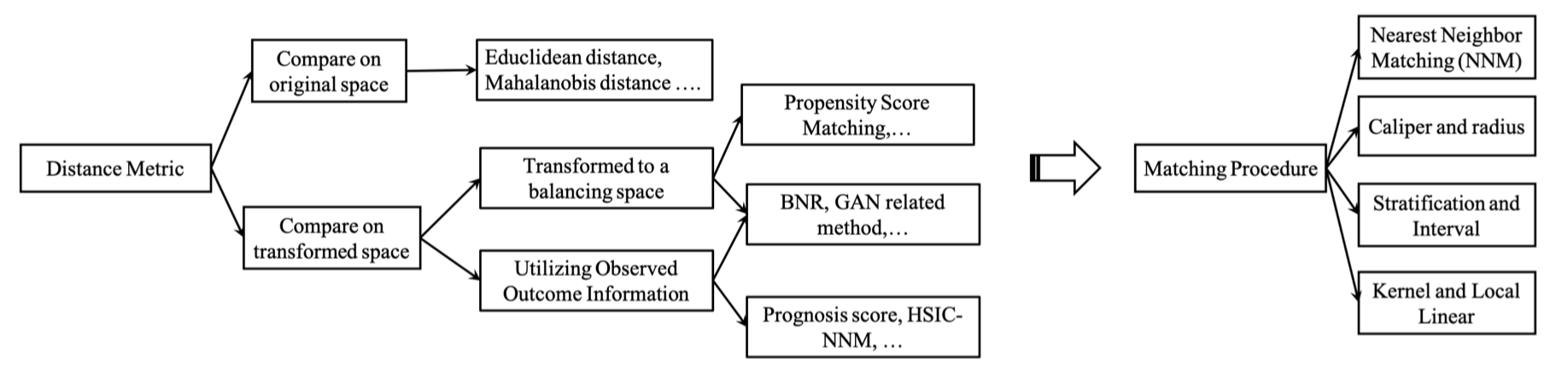
选择匹配算法
在定义了相似度度量方式后,下一步就是找出相似的邻居。现有的匹配算法可以被分为四类:最近邻匹配、卡钳匹配、分层匹配与核匹配。上图对经典的距离度量与匹配算法进行了总结。最常用的匹配算法是最近邻匹配(NNM),具体的步骤是基于相似度得分(例如倾向评分)选择对照组和干预组中最接近的单元进行匹配,干预组单元可以和一个对照组单元进行匹配,称为成对匹配或 1-1 匹配;也可以匹配到两个对照组,称为 1-2 匹配,以此类推。邻居数量的选择是一个权衡,高数量的邻居可能会导致干预效果估计器的高偏差与低方差,而低数量的邻居会导致低偏差与高方差。实际上最佳的结构应该是完全匹配的方式,即一个干预组可能对应多个对照组,而一个对照组可能对应一个或多个干预组。此外,NNM 存在多种变体,如可重置的 NNM(可重复匹配)与不重置的 NNM。
对 NNM 来说,如果最接近的邻居依然相差较远,那么匹配的结果可能会很差。一种可行的方法是设置一个容忍度等级,来限制最大可接受的相似度得分(原文中直接使用了倾向评分)距离,这种方法被称为卡钳匹配,其添加了一种共同支持条件。另一种方法是将上述共同支持条件划分为一组区间,然后基于干预组与对照组观测结果的平均差计算每个区间内的影响。这种方法被称为分层匹配,也称为区间匹配,分块(blocking)或子分层。
上述匹配方法的共同点在于只使用了对照组中的一小部分观测结果来计算干预组的反事实结果(反之亦然)。核匹配和局部线性匹配是两种非参数的匹配方法,其使用对照组中观测的加权平均来计算反事实结果。因此,这些方法的一大主要优点是低方差,因为我们利用了更多的信息来创建反事实结果。
此外,还有一种被称为广义精确匹配(CEM)的匹配方法。不论是 1-k 匹配或是完全匹配,都没有考虑到外推区域(extrapolation region),该区域的特征是其他的干预组中没有或很少有合理的匹配。为了解决这一问题,CEM 首先对选定的重要协变量进行离散化(粗化),然后针对粗化的协变量进行精确匹配。例如,如果选定的协变量是年龄(年龄大于 50 为 1,否则为 0)和性别(女性为 1,男性为 0),那么干预组中一位年龄是 51 岁的女性患者可以基于粗化协变量表示为 \((1,1)\)。该名患者只可能匹配到干预组中持有完全相同的粗化协变量的患者(注意是干预组内匹配)。在精确匹配后,整个数据被分为了两个子集,一个子集中每个单元都有其精确匹配的邻居,而另一个子集中则包含了位于外推区域中的单元(即不存在相似的单元接受过干预)。外推区域中单元的结果通过基于匹配子集训练得到的结果预测模型来估计。最后,将两个子集分别计算出的干预结果进行加权平均,得到最终的结果。
综上所述,我们已经介绍了各种不同的匹配算法,最重要的问题在于如何从其中选择一个完美的匹配方法。实际上,当样本量足够大时,所有的匹配方法都会趋向于给出精确的匹配,得出相同的结果。当我们只有较小数量的样本时,需要在偏差与方差之间进行权衡,选择最合适的算法。
纳入的变量
上面两小节说明了匹配过程中的两个关键步骤,本节将简单讨论在匹配中应该考虑哪些变量(即变量选择),以提高匹配性能。很多文献建议尽可能多地纳入与干预分配和结果相关的变量,以满足强可忽略性。然而,受干预分配影响的后干预变量应该被排除在外。此外,工具变量(instrumental variables)也建议进行排除(只影响干预分配不影响结果的变量),因为其可能会趋向于放大干预结果估计器的偏差。
基于树的方法
因果推断中的另一种经典方法即基于决策树学习的预测性建模。决策树是一种用于分类与回归问题的非参数监督学习方法,其目标是创建一个模型,通过从数据中学习简单的决策规则来预测目标变量的值。
目标变量是离散变量的树被称为分类树,其预测误差基于错误分类的损失进行度量。在分类树的结构中,叶子节点代表类的标签,分支则代表通向对应标签的特征的组合。目标变量是连续变量的树被称为回归树,其预测误差基于观察值与预测值的平方差进行度量。分类与回归树(CART)用于指代上述两个过程,在 CART 模型中,数据会被划分为多个空间并分别拟合一个简单的预测模型,因此每个子空间都可以被单独表示为一个决策树。
为了估计因果效应中的异质性,研究者们基于 CART 提出了一种数据驱动的方法,根据干预效果的差异,将数据划分为多个亚组(子空间)。即使在样本量较小的情况下(协变量数量较多),该方法依旧能够获得有效的干预效果置信空间(无需稀疏假设)。与传统 CART 相比,该方法的区别主要体现在:第一,其专注于估计条件平均干预效果,而非直接预测结果;第二,其使用不同的样本来构造分区并针对每个亚组估计效果,这被称为诚实估计(honest estimation),而在传统 CART 中,构造分区与估计效果使用的是相同的样本。
总体来看,在 CART 中,只存在一棵树,根据实际需求进行生长与修剪。下面将介绍几种树的集成模型。第一种是贝叶斯可加回归树(BART),其与梯度提升树(类似),基于序列性弱学习器的贡献加成进行学习,与对独立估计进行平均的随机森林模型相反。具体来说,BART 模型中的每棵树都是一个弱学习器,其受一个正则化先验约束。相关预测信息可以通过贝叶斯 backfitting MCMC 算法从后验中提取。从形式上看,定义 \(W\) 为一个包含一系列中间节点决策规则与终端节点的二元树,定义 \(M=\left\{\mu_{1}, \mu_{2}, \ldots, \mu_{B}\right\}\) 为与 \(W\) 中每 \(B\) 个终端节点相关联的参数。我们使用 \(g(x ; W, M)\) 来为输入向量 \(x\) 分配参数 \(\mu_{b} \in M\),则 BART 模型可以被表示为: \[ \begin{align*} Y=g\left(x ; W_{1}, M_{1}\right)+ g\left(x ; W_{2}, M_{2}\right)+&\cdots+g\left(x ; W_{m}, M_{m}\right)+\varepsilon, \tag{23} \\ \varepsilon \sim N\left(0, \sigma^{2}\right)& \tag{24} \end{align*} \] BART 的优点可以概括为:首先,其非常容易实现,只需要确定结果,干预分配与混杂因子即可;其次,其不需要关于这些变量在参数上如何关联的信息,在拟合模型时需要更少的猜测;第三,其可以处理大量的预测变量,产生连贯的不确定性区间,同时适用于连续型干预变量和缺失数据。从研究者给出的结果来看,BART 模型不仅可以在估计平均因果效应上优于倾向评分匹配,倾向评分加权等方法,还可以较容易地估计个体层面的异质干预效果(即CATE)。
与 BART 模型相反,随机森林(random forest)则是一系列树预测器的结合,其中每棵树依赖于一个独立采样的随机向量,其对于所有树保持相同分布。随机森林模型通常用于平均治疗效果的估计,而通过 Wager 等人提出的因果森林(causal forest)算法可以将该模型进一步用于估计异质干预效果。
总的来看,基于树(或森林)的算法可以视为一种邻居参数可调整的最近邻方法,其尝试去寻找距离点 \(x\) 最近的训练样本,但是其接近程度通过决策树进行定义。距离 \(x\) 最近的点即为归为相同叶子节点的样本。使用树的好处之一在于其叶子节点的约束可以在信号变化较快的方向上变严格而在其他方向上则适当放宽,从而潜在地适应更大的特征空间。此外,基于树的框架还可以扩展至一维或多维干预。
表征学习方法
平衡表征学习
在统计学习中,最基本的假设之一就是训练数据与测试数据应当来源于相同的分布,而在大部分的实际应用中,测试集数据只是来源于与训练数据相关(而非相同)的分布。在因果推断中,数据分布的差异体现在:由于干预分配在观察性数据中并不明确,受到潜在混在因子的影响,导致反事实分布与事实分布间通常存在差异。因此,我们需要通过学习事实数据来预测反事实结果,其将因果推断问题转变为了一个领域适应(domain adaptation)问题。
对于领域适应问题来说,提取有效的特征表示至关重要。研究者们提出了一种具有泛化约束的模型来从理论上形式化上述直觉,该模型不仅可以明确地最小化源领域与目标领域之间的差异,也可以最大化训练集的作用范围。基于这一模型,分布间的差异距离(discrepancy distance)可以通过任意的损失函数与领域适应问题相关联。
在因果推断的领域适应问题中,差异距离扮演着重要的角色。具体来说,一种直观的想法是加强表征空间中不同组别分布之间的相似性,而学习到的表征需要在以下三类目标上进行权衡:(1)事实表征的低误差预测;(2)反事实结果的低误差预测(考虑相关的事实结果);(3)干预组与对照组分布之间的距离。基于上述思路,有研究者给出了一种简单而直觉化的泛化误差约束,其表明表征所对应的期望 ITE 估计误差受该表征的标准化泛化误差之和以及基于表征的干预与对照分布之间的距离所约束。具体来说,该方法使用积分概率度量(IPM)来衡量分布之间的距离,以推导 Wasserstein 距离与 MMD 距离所对应的显示边界。其目标是找出一个表征 \(\Phi: X \rightarrow R\) 与假设 \(h: X \times\{0,1\} \rightarrow Y\) 以最小化如下目标函数: \[ \min _{h, \Phi} \frac{1}{n} \sum_{i=1}^{n} r_{i} \cdot L\left(h\left(\Phi\left(x_{i}\right), W_{i}\right), y_{i}\right)+\lambda \cdot R(h)+\alpha \cdot \operatorname{IPM}_{G}\left(\{\Phi(x_{i})\}_{i: W_{i}=0},\{\Phi(x_{i})\}_{i: W_{i}=1}\right) \tag{25} \] 其中 \(w_{i}=\frac{W_{i}}{2 u}+\frac{1-W_{i}}{2(1-u)}\),\(u=\frac{1}{n} \sum_{i=1}^{n} W_{i}\),权重 \(r_i\) 用于补偿干预组之间的规模差异,\(R\) 是模型复杂度项。给定两个定义在 \(S \subseteq R^{d}\) 上的概率密度函数 \(p, q\),则对于函数 \(g: S \rightarrow R\) 的函数族 \(G\),IPM 定义为: \[ \text{IPM}_{G}(p, q):=\sup _{g \in G}\left|\int_{S} g(s)(p(s)-q(s)) d s\right| \tag{26} \] 上述模型可以学习复杂的非线性表征与假设,且具有较高的灵活性。当 \(\Phi\) 的维数较高时,如果将 \(\Phi\) 与 \(W\) 的连接作为输入,则干预对假设的影响可能会消失。为了解决这个问题,上述模型的原作者提出了一种方法,建立了一种包含 \(h_1(\Phi)\) 与 \(h_0(\Phi)\) 两个分离头部的联合网络,其中 \(h_1(\Phi)\) 用于估计干预组的结果,\(h_0(\Phi)\) 则用于估计对照组的结果,每个样本只用于更新其实际干预所对应的头部。此外,多个研究表明,该模型还可以被扩展至任意数量的干预,并与其他的方法相结合(此处不作展开)。
总的来看,现有的 ITE 估计方法主要聚焦在平衡对照组与干预组的分布,忽略了为 ITE 估计提供有用约束的局部相似度信息。有研究者基于深度表征学习提出了一种保留局部相似性的 ITE 估计方法(SITE)。SITE 在平衡数据分布的同时保持了局部相似性,其框架包含 5 个主要部件:表征网络、三元组对选择、位置-依赖深度度量(PDDM)、中点距离最小化(MPDM),以及结果预测网络。为了提升模型效率,SITE 以小批量的形式输入单元,从每一批中选择三元组;表征网络从输入单元中学习潜在嵌入;根据所选择的三元组,PDDM 与 MPDM 可以保留局部相似度信息,同时在潜在空间中获得平衡的分布;最终,学习得到的小批量的嵌入被传入结果预测网络中以得到潜在的结果。SITE 的损失函数如下: \[ L=L_{FL}+\beta L_{P D D M}+\gamma L_{M P D M}+\lambda\|M\|_{2} \tag{27} \] 其中 \(L_{FL}\) 是估计与观察事实结果之间的事实损失,\(L_{P D D M}\) 与 \(L_{MPDM}\) 分别是 PDDM 与 MPDM 的损失函数,最后一项是对模型参数 \(M\) 的 \(L_2\) 正则化约束。
另一方面,大部分模型都聚焦在数值变量的协变量,如何在估计干预效果时处理包含文本信息的协变量依旧是一个开放性问题。一个主要的挑战是如何过滤掉接近工具变量的变量(即对干预分配的影响大于结果),以这些变量为条件进行干预效果估计会放大估计偏差。为了应对这一挑战,研究者们提出了一种基于干预对抗学习的匹配方法(CTAM),CTAM 引入干预对抗学习以在学习表征时滤除近似工具变量,并在学习到的表征间进行匹配以估计干预效果。CTAM 包含 3 个主要部件:文本处理、表征学习、条件干预判别器。通过文本处理组件,原始文本会被转化为向量表示 \(S\);随后 \(S\) 与非文本协变量 \(X\) 相连接以构建统一的特征向量,其被输入表征神经网络以获得潜在表征 \(Z\);在学习到表征后,\(Z\) 与潜在结果 \(Y\) 一起输入到条件干预判别器中。在训练过程中,表征学习器与条件干预判别器进行最小最大博弈:通过防止判别器分配正确的干预,表征学习器可以滤除与近似工具变量相关的信息。最终的匹配过程在表征空间 \(Z\) 中进行。总的来看,条件干预-对抗学习可以帮助减少干预效果估计的偏差。
在表征学习类方法中,部分方法在学习到表征后使用基于回归的方法生成最终结果,而部分方法则采用基于匹配的方法。与回归方法相比,匹配方法的可解释性更强,因为任意样本的反事实结果都直接设置为接受相反干预的组中的最近邻的事实结果,即最近邻匹配算法(NNM)。虽然这种方式简单易懂,但其非常容易被与结果无关的变量所误导。为了应对这一挑战,可以在能够同时预测干预组与对照组结果变量的子空间进行匹配。在学习到的子空间应用 NNM 算法可以获得更加精准的反事实结果估计,从而获得更精准的干预效果估计。有研究者通过学习一个最大化子空间与对照样本结果变量之间非线性依赖的映射矩阵来估计干预样本的反事实结果,然后直接将学习到的映射矩阵应用到所有的样本来找出子空间中与每个干预样本相对应的对照样本。
多任务学习方法
对于干预组与对照组来说,其通常共享一些通用的特征,同时各自保有一些异质性的特征。自然地,因果推断可以被理解为一个多任务学习问题,其包含面向干预组与对照组的共享层集合,以及分别面向各组的特定层集合。在多任务学习问题中,选择偏差的影响可以通过一种倾向-dropout 正则化机制进行缓解,该机制通过依赖于相关联倾向评分的 dropout 概率为每个训练样本进行网络结构优化(随机去除单元),如果样本的特征在干预组与对照的特征空间中重叠较低,则其对应的 dropout 概率会偏高。
贝叶斯方法同样可以在多任务模型中得到应用。有研究者提出了一种非参数贝叶斯方法,其使用包含线性共区域化核的多任务高斯过程作为向量化再现核 Hilbert 空间上的先验,能够允许通过逐点可信区间计算估计中的个性化置信度量,实现更加精准的效果预测。选择偏差的影响则可以通过基于风险的经验贝叶斯方法进行缓解,其联合最小化事实结果中的经验误差以及反事实结果中的不确定性。
此外,多任务模型还可以被扩展至多重干预与包含连续性参数的干预。有研究者提出了一种剂量响应网络(DRNet),其具有共享的基础层,\(N_W\) 层中间干预层,以及 \(N_W \times E\) 个用于多重干预设置的头部(及其关联剂量参数 \(s\))。共享基础层在所有样本上进行训练,干预层只在其对应的干预类别的样本上进行训练。每个干预层进一步被分为 \(E\) 个头部层,每个头部层被分配一个剂量范围,其将潜在的剂量范围 \([a_t, b_t]\) 划分为 \(E\) 个等宽区间。
元学习方法
在设计异质干预效果(即条件干预效果)估计算法时,应当考虑以下两个关键要素:
- 控制混杂因子,即消除混杂因子与结果之间的伪关联(以及选择偏差)
- 给出 CATE 估计的准确表达式
之前章节所给出的方法尝试去同时满足上述两个要素,而基于元学习(meta-learning)的算法会将上述要素分为两个步骤实现:
- 估计条件平均结果 \(\mathbb{E}[Y \mid X=x]\),该步骤中学习得到的预测模型为基学习器(base learner)
- 基于第一步中结果的差异推导 CATE 估计器
现有的用于异质干预效果估计的元学习算法包括 T-learner、S-learner、X-learner、R-learner 等,下面将对这些算法进行详细介绍。
T-learner 采用两棵树来估计条件干预/对照结果,分别记作 \(\mu_{0}(x)=\mathbb{E}[Y(0) \mid X=x]\) 与 \(\mu_{1}(x)=\mathbb{E}[Y(1) \mid X=x]\)。令 \(\hat{\mu_{0}}(x)\) 与 \(\hat{\mu_{1}}(x)\) 表示针对对照组与干预组训练的树模型(这里原文有一个符号错误)。T-learner 的 CATE 估计可以通过 \(\hat{\tau}_{T}(x)=\hat{\mu}_{1}(x)-\hat{\mu}_{0}(x)\) 得到。T-learner 得名的原因是其训练了面向对照组与干预组的两个(two)基础模型,而 S-learner 则将干预分配视为一项特征,估计组合结果:\(\mu(x, w)=\mathbb{E}\left[Y^{F} \mid X=x, W=w\right]\)("S" 表示 single)。\(\mu(x,w)\) 可以是任何基础模型,训练完成的模型记作 \(\hat\mu(x,w)\)。由 S-learner 提供的 CATE 估计器可以表示为:\(\hat{\tau}_{S}(x)=\hat{\mu}(x, 1)-\hat{\mu}(x, 0)\)。
然而,T-learner 与 S-learner 高度依赖于训练得到的基础模型的表现,当干预组与对照组单元数量相差较大时,较小组训练得出的基础模型可能会表现较差。为了解决这一问题,研究者提出了 X-learner,其利用对照组的信息来为干预组进行更好地估计(反之亦然),"X" 表示 cross group。具体来说,X-learner 包含三个关键步骤:第一步与 T-learner 相同,训练处的基学习器记作 \(\hat{\mu_{0}}(x)\) 与 \(\hat{\mu_{1}}(x)\);第二步中,X-learner 计算观测结果与估计结果之间的差异,将其作为估计干预效果:对于对照组,差异为估计干预结果减去观测对照结果:\(\hat{D}_{i}^{C}=\hat{\mu}_{1}(x)-Y^{F}\);类似地,对于干预组有,差异为:\(\hat{D}_{i}^{T}=Y^{F}-\hat{\mu}_{0}(x)\)。计算出差异后,数据集被转化为包含估计干预效果的两组:对照组 \((X_C,\hat{D}^C)\) 与干预组 \((X_T,\hat{D}^T)\)。基于上述两个估计数据集,分别训练两个干预效果的基学习器 \(\tau_1(x)\) 与 \(\tau_0(x)\) ,以 \(X_C\)(或 \(X_T\))作为输入,以 \(\hat{D}^C\)(或 \(\hat{D}_{i}^{T}\))作为输出。在最后一步中,通过加权平均将上述两个 CATE 估计器进行结合:\(\tau_{X}(x)=g(x) \hat{\tau}_{0}(x)+(1-g(x)) \hat{\tau}_{1}(x)\),其中 \(g(x)\) 为范围在 0-1 之间的权重函数。总的来看,通过交叉信息的使用以及两个 CATE 基估计器的加权,X-learner 能够较好地处理干预组与对照组单元数量分布不平衡的情况。
不同于 X-learner 中采用的常规损失函数,R-learner 基于 Robinson 变换进行损失函数设计(其名称也来源于此),Robinson 变换可以通过重写观测结果与条件结果来得到。具体来说,将观测结果重写为: \[ Y_{i}\left(W=w_{i}\right)=\hat{\mu}_{0}\left(x_{i}\right)+w_{i} * \tau\left(x_{i}\right)+\epsilon_{i}\left(w_{i}\right) \tag{28} \] 其中 \(\hat{\mu}_{0}\) 是训练完成的对照结果估计器(基学习器),\(\tau\left(x_{i}\right)\) 是 CATE 估计器,且 \(E\left[\epsilon_{i}\left(w_{i}\right) \mid x_{i}, w_{i}\right]=0\)(基于可忽略性假设)。条件平均结果可以被重写为: \[ \hat{m}\left(x_{i}\right)=E[Y \mid X]=\hat{\mu}_{0}\left(x_{i}\right)+\hat{e}\left(x_{i}\right) * \tau\left(x_{i}\right) \tag{29} \] 其中 \(\hat{e}\left(x_{i}\right)\) 是训练完成的倾向评分估计器(基学习器)。Robinson 变换通过上述两式相减得到: \[ Y_{i}^{F}-\hat{m}\left(x_{i}\right)=\left(w_{i}-\hat{e}\left(x_{i}\right)\right) \tau\left(x_{i}\right)+\epsilon\left(w_{i}\right) \tag{30} \] 基于 Robinson 变换,一个好的 CATE 估计器应当最小化 \(Y_{i}^{F}-\hat{m}\left(x_{i}\right)\) 与 \(\left(w_{i}-\hat{e}\left(x_{i}\right)\right) \tau\left(x_{i}\right)\) 之间的差异。因此,R-learner 的目标函数如下: \[ \tau(\cdot)=\underset{\tau}{\arg \min }\left\{\frac{1}{n} \sum_{i=1}^{n}\left(\left(Y_{i}^{F}-\hat{m}\left(x_{i}\right)\right)-\left(w_{i}-\hat{e}\left(x_{i}\right)\right) \tau\left(x_{i}\right)\right)^{2}+\Lambda(\tau(\cdot))\right\} \tag{31} \] 其中 \(\hat{m}(x_i)\) 与 \(\hat{e}(x_i)\) 分别是预训练结果估计器与倾向评分估计器,\(\Lambda(\tau(\cdot))\) 是正则化项。
无假设的因果推断方法
上一节详细介绍了在三类基本假设下的各种因果推断方法,然而在实践中,对于某些特定场景下的应用,例如包含依赖性网络信息、特殊数据类型(如时间序列)或特殊条件(例如存在未观测混杂因子)时,三类假设并不总是能全部满足。本节将介绍在这些假设不满足情况下的因果推断方法。
稳定单元干预值假设
稳定单元干预值(SUTVA)假设表明,任意单元的潜在结果都不会因其他单元的干预发生改变而改变,且对于每个单元,其所能接受的每种干预不存在不同的形式或版本,不会导致不同的潜在结果。该假设主要聚焦在两个方面:
- 每个单元是独立同分布的(i.i.d.)
- 每种干预只存在单一版本
下面将从上述两方面分别展开讨论如何在不满足假设的条件下进行因果推断。
独立同分布假设在大部分因果推断方法中存在,但是在部分研究领域,该假设并不成立,例如社交媒体分析、群体免疫、信号处理等。由于混杂因子与数据依赖的同时存在,非 i.i.d 下的因果推断是具有挑战性的。以社交网络分析为例,其中每个对象都是相互关联且相互影响的,在这样的情况下,实例之间通过网络结构形成内在的连接,其特征并不满足独立同分布。将图神经网络与因果推断模型相结合是处理网络数据的一种可行方法。具体来说,对象的原始特征与网络结构会被映射到一个表征空间中,以得到混杂因子的表征。进一步地,使用干预分配与混杂因子表征来推断最终的潜在结果。此外,由于部分对象的干预会影响到其他对象的结果,数据的依赖性通常会对因果参数的识别与估计带来干扰,有研究者提出了分离图(segregated graph)策略来解决这一问题,其是潜在映射混合图的推广,用来对因果模型进行表示。
另一方面,时间序列数据也不满足独立同分布假设,同样是因果推断中的一个重要问题。大部分现存的方法使用回归模型来解决这一问题,但是推理的准确性高度依赖于模型是否能够很好地拟合数据。因此,选择一个正确且合适的回归模型是非常重要的,然而在实践中,找到这样的模型并不容易。有研究者提出了一种监督学习框架,其使用分类器来替代回归模型,具体来说,其提出了一种基于给定过去变量值的条件分布之间距离的特征表示,并通过实验表明该特征表示能够为不同因果关系的时间序列提供足够不同的特征向量。对于时间序列来说,另一个需要考虑的问题是隐藏混杂因子(实际上这属于第二种假设,原文在第二节中又描述了一次这篇研究),有研究者提出了一种时间序列去混杂器,其利用时序性执行的多重干预分配来在存在隐藏混杂因子的情况下估计干预效果。该时间序列去混杂器采用基于多任务输出的循环神经网络架构来构建时序性因子模型,推理出替代的混杂因子,以保证所分配的干预条件独立;随后,利用所获得的替代混杂因子执行因果推断。
对于 SUTVA 假设中的第二个方面,其假定每种干预只存在一个版本,然而,如果向干预中添加一个连续型(或离散型)参数,则该假设并不会再成立。例如,在估计一系列药物治疗的个体剂量反应曲线时,为每种治疗添加一个相关联的剂量参数(连续型或类别型),则其对于类别型参数会存在多个版本,而对于连续型参数则会存在无限个版本。解决上述问题的一种方法是将连续型剂量转变为类别变量,并将特定剂量的用药方案视为一种新的干预,以满足 SUTVA 假设。
另一种不满足 SUTVA 的案例是动态治疗策略(dynamic treatment regime),其包含多个干预阶段,由一系列决策规则构成。动态治疗策略的典型应用场景是精准用药,其能够根据患者的个体特征提供更加个性化的用药方案与计量控制,并随着时间的推移不断调整,以持续获得最优治疗策略。这些异质性特征被称为定制变量(tailoring variables)。为了获得有用的动态治疗策略,研究者们提出了一种偏差自适应内部随机化设计,并使用序列性多重分配随机试验(SMART)给出了这类设计的通用性框架,在 SMART 中,每个个体会被执行多次随机化(序列性发生)以制定决策规则。
为了从观察性数据中估计最优动态决策规则,常用的两种方法是 Q 学习与 A 学习。Q 学习是强化学习领域的经典无模型方法,其在给定单元信息的每个决策点上使用假定的回归模型估计结果;而在 A 学习中,模型仅针对部分回归(包括干预之间的对比)以及给定单元信息的每个决策点的观测干预分配概率进行制定。两种方法都是通过与动态规划相关的反向递归拟合过程进行实现。
可忽略性假设
可忽略性假设也被成为无混淆假设,指给定背景变量 \(X\),干预的分配 \(W\) 独立于潜在结果,即 \(W \perp \!\!\! \perp Y(W=0), Y(W=1)|X\)。在该假设下,对于具有相同背景变量 \(X\) 的单元,其干预分配可以视为随机。显然,识别并收集所有的背景变量是不可能的,因此该假设很难被满足。例如,在一项尝试去估计个体药物治疗效果的观察性研究中,药物的分配方式是综合个体的一系列因素完成的,部分因素(例如社会经济地位)很难衡量,从而变成了隐藏的混杂因素。现有的研究大部分遵循无混淆假设,即所有的混杂因子均被度量,但实际上这并不能实现。利用大数据,我们能够通过代理的方式来处理这些潜在的未观测混杂因子。
有研究者使用变分自编码器(variational autoencoder)来推理观测混杂因子与潜在混杂因子、干预分配及结果联合分布之间的复杂非线性关系。另一种方式是通过网络信息来捕捉观测混杂因子与潜在混在因子之间的模式关系,有研究者使用了图卷积神经网络来获得隐藏混杂因子的表征;还有研究者使用图注意力层来将网络化观察性数据中的观测特征映射到部分潜在混杂因子的 D-维空间中,通过捕捉网络化观察性数据中的未知边权重。
此外,有研究者指出,即使混杂因子被观测到,也不意味着其包含的所有信息都对因果推断有利,有时估计器只需要混杂因子的部分特征。因此,如果可以构建了一个好的干预效果预测模型,则可能只需要将输出直接插入到因果效应估计中,而无需学习真正的混杂因子。该篇文章将因果估计问题化简为一个针对干预与结果的半监督预测问题,通过高质量嵌入模型来替代完全确定的生成模型,应用于半监督预测。
只利用观察性数据来解决混杂因子问题通常是较困难的,另一种解决思路是将实验数据与观察性数据进行结合。有研究者利用有限的实验数据来纠正基于大量观察性数据所训练出的因果效应模型的隐藏混杂因素,即便观察性数据与实验数据并不完全吻合。该方法与现有的方法相比采用了更弱的假设。
总的来看,上述方法均旨在解决关于观测与未观测混杂因子的问题,下面介绍一种绕过无混淆假设执行因果推断的方法。我们可以使用工具变量(instrumental variables),其只会对干预分配产生影响。工具变量的变化会导致不同的干预分配,其独立于潜在变量,而该干预分配可以视为用于因果推断的随机化。有研究者将工具变量分析拆分为两个监督式阶段,通过深度神经网络实现。其首先对给定工具变量与其他协变量的干预变量的条件分布进行建模,使用包含针对条件干预分布的积分的损失函数进行训练,然后利用现有的监督学习技术来估计因果关系。
正值假设
正值假设,也被称为协变量重叠或共同支持,指对于任意值的 \(X\),干预分配都不是确定的。其是在观察性研究中识别干预效果的必要假设,然而其在高维数据集中的满足情况却鲜有研究讨论。有研究者指出,正值假设属于一种强假设,在高维数据集中很难满足,为了支持该主张,该研究又讨论了严格重叠假设,表明严格重叠限制了对照与干预协变量之间的一般差异。因此,正值假设要强于研究人员的预期。基于上述结论,建议在高维数据集中采用能够消除干预分配信息同时保留无混淆假设的方法,例如修剪(trimming)方法(删除未重叠区域的记录)、工具变量调整方法(从协变量中消除工具变量)等。
常用数据集及代码库
本节将提供进行因果推断研究的相关实验信息,包括可获得的公开数据集,以及部分经典方法的开源代码库。
公开数据集
由于反事实结果永远不可能被观测到,因此很难找到包含真实 ATE 的观察数据集。因果推断研究所采用的观察性数据集通常是半合成的:部分数据集(例如 IHDP)通过随机数据集(RCT试验)生成得到,采用固定的生成过程,并从中移除有偏子集来模拟观测数据中的选择偏差;部分数据集则将随机数据集与观测对照数据集结合起来以创造选择偏差。下面对部分常见的数据集进行总结。
IHDP。该数据集基于面向低体重早产儿的 RCT 试验数据构建。预干预协变量共有 25 种,包括出生体重、头围、新生儿健康指数、母亲年龄、教育水平、用药、饮酒情况等。干预组为新生儿提供了强化的高质量儿童护理与专家上门服务。结果变量是新生儿的认知测试得分。为了模拟选择偏差,去除了干预组的一个有偏子集。
Jobs。该数据集是 Lalonde 试验数据集与 PSID 对照数据集的结合。预干预协变量共有 8 种,包括年龄、教育水平、种族、收入等。干预组接受了工作培训而对照组则没有。结果变量是就业情况。
Twins。该数据集根据在 1989-1991 年间美国双胞胎出生的数据所构建,性别相同且体重小于 2000g 的双胞胎会被纳入记录。对于每对双胞胎,共有 46 个预干预变量,包括妊娠周数、孕期护理质量、怀孕风险因素、居住情况等。双胞胎中较重的新生儿视为干预组,结果变量是新生儿一年的死亡率。选择偏差通过用户自定义的干预分配机制(隐藏部分数据)来进行模拟。
BlogCatalog。该数据集用于网络化观测数据的因果推断。其是一个社交博主网络,每个博主都是一个观测,通过某种社会关系相关连接。博主的描述通过关键词的词袋模型表示为特征。结果变量是读者对每个博主的评价,如果该博主的博客在移动设备(桌面)上阅读更多,则其属于干预组(对照组)。
Flickr。该数据集同样是网络化观测数据,基于图片分享平台 Flickr 构建。拥有 Flickr 账户的用户是观测,通过某些社会关系与其他用户连接。每个用户的特征是其兴趣标签,干预分配与结果变量与 BlogCatalog 相同。
News。该数据集包含了 5000 篇从纽约时报语料库汇总随机抽取的新闻文章。其进一步包含读者对于新闻的观点数据,最初被用于在两种干预选项下的反事实推理。在后续研究中被扩展至具有相关剂量参数的多重干预。
MVICU。该数据集用于估计与剂量参数关联的多种干预下的个体剂量反应曲线。其包含患者对于重症监护室中不同机械通气配置的反应。数据集来源于知名的 MIMIC III 数据库,包含了 ICU 患者的各类数据。
TCGA。该数据集是世界上最大的基因数据集合,其收集了 9659 位不同癌症患者的基因表达数据。该数据集同样可以用于估计与剂量参数关联的多种干预下的个体剂量反应曲线(上述三个数据集与剂量相关的因果效应估计均出自同一文章)。干预选项为用药、化疗与手术,结果变量是接受干预后的癌症复发风险。
THE。该数据集是一项为其四年的纵向班级规模研究,用来度量班级规模对学生成绩与其他方面的影响。由于这是一个随机对照试验,所以需通过移除有偏子集的方式来人工引入混杂因子。
FERTIL2。该数据集的目标是研究妇女接受超过七年(或恰好七年)的教育对家庭中子女数量的影响。其包含多个观测混杂因子,如年龄、是否拥有电视、是否居住在城市等。工具变量是一个表示妇女是否在上半年出生的二元指示器。该数据集通常用于工具变量的研究。
开源代码库
本节总结了之前所述的各类因果推断方法的开源代码以及包含多种方法的工具包,因果推断领域的常用工具包如下表所示,关于具体方法的开源代码可以参考原文,此处不作展开。
| 工具包名称 | 支持方法 | 语言 |
|---|---|---|
| Dowhy | 倾向回归分层 & 匹配、逆倾向加权、回归方法 | Python |
| Causal ML | 基于树的方法,元学习方法 | Python |
| EconML | 双重稳健估计器、正交随机森林、元学习方法、深度工具变量 | Python |
| causalToolbox | 贝叶斯可加回归树、因果森林、基于树的元学习器 | R |
应用
在现实世界场景中,因果推断有着各种各样的应用。总的来看,因果推断的可以总结为以下三个方向:
- 决策评估。干预效果估计的目的就是评价干预的有效性,因此与干预相关的决策评估自然是因果推断的应用方向之一。
- 反事实估计。反事实学习对决策支持相关领域有着重要作用,其可以提供不同决策选择的潜在结果。
- 处理选择偏差。在很多真实世界应用中,出现在所收集数据集中的记录并不能够代表整个目标群体。如果不能很好地处理这一选择偏差,则会大大影响所训练模型的泛化性。
下面将详细介绍几个因果推断方法在真实世界应用中的具体领域。
广告
正确衡量广告活动的效果可以回答关键的营销问题,例如新广告是否会增加点击数或增加销量。由于开展随机试验的成本过高,基于观察性数据估计广告效果在工业界和学术界引起了越来越多的关注。举例来说,有研究者提出了随机最近邻匹配方法来估计数字化营销活动的干预效果;有研究者使用协变量平衡广义倾向得分(CGBPS)来分析政治广告的效力。
然而,对于在线广告领域,通常需要处理复杂的广告干预形式,包括离散或连续、一维或多维等。我们可以将一个广告设置为一种基线干预,然后通过比较不同值的干预与基线干预的潜在结果来估计干预效果。为了估计多维值干预下的潜在结果,研究者采用了基于树的方法与基于稀疏加性模型的方法来实现潜在治疗与基线治疗之间的比较。
除了纯净的观察性数据,在真实世界场景中,数据集还可能由来自对照组的大量样本与来自随机试验(同时包含对照与干预)的少量样本组成(类似上一节中公开数据集的构建方法)。有研究者使用最小化的建模假设集合将随机试验数据集与对照数据集进行结合,使得模型在预测对照与试验结果上保持相似的性能。在这一假设下,其所提出的方法联合学习对照与干预结果预测器,并对两个预测器参数之间的差异性进行正则化。
以上讨论描述了因果推断方法在决策估计方向上的潜在应用:衡量广告活动的效果。其在广告领域的另一个研究方向是处理选择偏差。由于广告系统中的选择机制,展示事件(广告)与未展示事件之间存在着分布差异,忽略这种偏差可能会导致广告点击预测的不准确,从而引起经济损失。为了处理选择偏差,有研究者提出了类似 3.1.1 节双重稳健估计方法的双重稳健策略学习,其包含两个子估计器:从个观测样本得到的直接方法估计,以及将倾向评分作为样本权重的 IPS 估计器。
此外,一些研究防线由于商业广告系统中的确定性广告投放策略,倾向评分估计可能会存在困难。如果投放策略是随机的,低倾向评分的广告依旧有机会出现在观察性数据中,以帮助 IPS 纠正选择偏差;然而如果投放策略是确定的, 低倾向评分的广告则总是不会出现在观测中,使得倾向评分估计失败。为了解决这一问题,有研究者提出了无倾向双重稳健方法,其从以下两个方面对原始的双重稳健方法进行了改进:
- 基于在统一策略下获得的少量无偏数据训练直接方法,一定程度上避免选择偏差传播到未显示的广告
- 通过将观测项的倾向评分设置为 1 避免倾向评分估计,并将 IPS 与直接方法结合
简单来说,上述无倾向评分方法依赖于基于无偏小数据集训练的直接方法,来获得广告点击的无偏预测。除了上述应用,广告领域的另一个重要应用是广告推荐,将合并至下一小节进行介绍。
推荐
推荐与干预效果估计高度相关,在推荐系统中向一名用户展示一个物品可以视作将一个特定的干预应用于一个单元。与治疗效果估计中使用的数据集类似,推荐中使用的数据集通常由于用户的自我选择而存在偏差。例如在电影评分数据集中,用户倾向于为其喜爱的电影评分;而在广告推荐数据集中,推荐系统只会向其认为对广告感兴趣的用户进行推荐。在上述案例中,数据集中的记录并不代表整个群体,即出现了选择偏差。选择偏差为推荐模型训练与评估带来了挑战。基于倾向评分的重加权样本可以有效解决该问题,执行倾向评分加权后的改进效果估计可以通过下式计算: \[ \hat{R}_{\mathrm{IPS}}(\hat{Y} \mid P)=\frac{1}{U \cdot I} \sum_{(u, i): O_{u, i}=1} \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} \tag{32} \] 其中 \(\hat{Y}\) 是推荐系统质量的度量值,\(U\) 是用户数量,\(I\) 是物品数量,\(O_{u,i}\) 是表明观察性数据中第 \(u\) 个用户与第 \(i\) 个物品的交互情况的二元变量,\(\delta_{u, i}(\cdot, \cdot)\) 可以是任何推荐质量的度量方式,例如累积增益(CG)、折扣累积增益(DCG)、第 k 精准率等,\(P\) 是边际概率矩阵,其项定义为 \(P_{u, i}=P\left(O_{u, i}=1\right)\)。上述改进后的质量度量是对整个群体上真实度量 \(R(\hat{Y})\) 的无偏估计,其定义为 \(R(\hat{Y})=\frac{1}{U \cdot I} \sum_{u=1}^{U} \sum_{i=1}^{I} \delta_{u, i}(Y, \hat{Y})\)。有研究者基于该无偏质量度量提出了用于推荐的倾向评分经验风险最小化(ERM)方法:选择 \(\hat{Y} \in \mathcal{H}\) 用于以下问题的优化:\(\hat{Y}^{E R M}=\operatorname{argmin}_{\hat{Y} \in \mathcal{H}}\left\{\hat{R}_{\mathrm{IPS}}(\hat{Y} \mid P)\right\}\),其中 \(\hat{R}_{\mathrm{IPS}}(\hat{Y} \mid P)\) 如式 (32) 中所定义。其后,又涌现出一些研究来解决倾向评分加权的缺陷,包括估计方差降低、数据稀疏性处理、双重稳健估计等。
除了使用基于 IPS 或双重稳健估计的方法来解决选择偏差之外,与广告领域类似,一些研究采用小型无偏数据集来纠正选择偏差。在该案例中, 数据集包含在对照策略下的大量反馈记录以及在随机推荐下的少量记录里。CausalEmbed(CausE)是这一方向的一个代表性方法,其提出了一种全新的矩阵分解算法,通过联合分解上述两个数据集构成的矩阵,并通过正则化干预与对照组表征之前的差异来连接两个模型。
医学
学习治疗每位患者的最佳治疗规则是在医学领域应用干预效果估计方法的终极目标。当不同药物(治疗)的效果可以被估计时,医生能够针对性地开具更加合理的处方。有研究者提出了为实现这样的目标需要面临的两个挑战:混杂因子的存在以及未观测混杂因子的存在。虽然基于随机对照试验数据集进行分析是最佳解决方案,但其存在一定的局限性:
- 随机对照试验的目标是估计 ATE 而非 ITE,数据量通常较少,限制了推导个性化治疗规则的能力
- 如第二节中所述,开展随机对照试验的成本过高,有时还存在伦理问题
因此,从观察性数据集中推导个性化治疗规则以及将试验性数据与观察性数据结合是两个较为热门的研究方向。对于利用观察性数据集的方向,多项研究在无混淆假设下基于估计的 ITE 来推导个性化治疗规则。不过处理未观测混杂因子的研究相对较少,尚待进一步探索。
强化学习
从强化学习的角度来看,ITE 估计可以视为一种上下文多臂赌博机问题,其中干预是动作(action),结果是奖励(reward),背景变量则是上下文信息。赌博机问题的开发与试探(exploration and exploitation)同随机试验与观察性数据类似。因此,这两个领域共享类似的挑战:
- 如何获得无偏的结果 / 奖励估计?
- 如何处理观测或未观测混杂因子对干预分配 / 动作与结果 / 奖励的影响?
对于第一个挑战,重要性采样加权是离线策略评估中常用的方法。权重被设置为目标策略与观测策略之间的概率,类似于 IPW 方法。不过,该方法受困于较高的方差,同时高度依赖于分配的权重。为了改善这一点,类似于 ATE 估计中的双重稳健方法,有研究者提出了双重稳健策略估计(6.1 节有提到)。其后,还有大量研究在不同的设置下对上述两种方法进行改进。
对于第二个挑战,当所有的混在因子被观测到时,我们可以直接使用上一段提到的方法优化无偏奖励。然而,当存在未观测混杂因子时,其可能会导致引入危害而非收益的策略,如同观察性数据一样。有研究者提出了混杂-稳健学习框架,在倾向性权重的不确定集合上优化策略,以控制未观测的混在因子。
其他应用
因果推断的应用并不局限于上述领域,与效果衡量、决策制定、选择偏差处理相关的领域均是潜在的应用方向,例如:
教育。在教育领域,通过比较不同教学方法对学生的效果,可以选择更好的教育方法。此外,ITE 估计可以通过估计不同教育方法对每个学生的结果来强化个性化学习。
政策性决策。因果推断可以帮助决定一项政策是否应当推广至大量人口。例如,多项研究基于 Jobs 数据集来考察“谁将从免费工作培训中受益最大”这一问题。
提升机器学习方法。各类用于处理选择偏差的平衡方法可以用来提升机器学习方法的稳定性。例如,有研究采用重加权方法来提升学习到的模型在未知环境中的泛化能力。
总结
因果推断是一个历史悠久的研究方向,其为发现真实世界中的因果关系提供了一种有效的方式。如今,机器学习的蓬勃发展为这一领域带来了新的活力,同时,因果推断中的思想也促进了机器学习的发展。本综述对潜在结果框架下的因果推断方法进行了较为全面的总结,全文的思维导图如下: